머신러닝(Machine Learning)
지도 학습(Supervised Learning)
- 데이터에 라벨이 있는 경우 사용할 수 있다.
분류(Classification)
- 주어진 데이터의 카테고리 혹은 클래스 예측을 위해 사용된다.
회귀(Regression)
- 컨티뉴어스(Continuous)한 데이터를 바탕으로 결과를 예측하기 위해 사용된다.
비지도 학습(Unsupervised Learning)
클러스터링(Clustering)
- 데이터의 연관된 피쳐를 바탕으로 유사한 그룹을 생성한다.

차원 축소(Dimensionality Reduction)
- 높은 차원을 갖는 데이터셋을 사용하여 피쳐 선택(Feature Selection), 추출(Extraction) 등을 통해 차원을 줄이는 방법이다.
연관 규칙 학습(Association Rule Learning)
- 데이터셋의 피쳐들의 관계를 발견하는 방법이다.
강화 학습(Reinforcement Learning)
- 머신러닝의 한 형태로 기계가 좋은 행동에 대해서는 보상, 그렇지 않은 행동에는 처벌이라는 피드백을 통해, 행동에 대해 학습해 나가는 형태이다.
치트 시트

클러스터링(Clustering)
- 클러스터링은 비지도 학습 알고리즘의 한 종류이다.
목적
- 클러스터링이 대답할 수 있는 질문은 주어진 데이터들이 얼마나, 어떻게 유사한 지 이다.
- 주어진 데이터셋을 요약, 정리하는데 있어 매우 효율적인 방법들 중 하나로 사용되고 있다.
- 동시에 정답을 보장하지 않는다는 이슈가 있어서 프로덕션(Production)의 수준, 혹은 예측을 위한 모델링에 쓰이기 보다 EDA를 위한 방법으로서 많이 쓰인다.
종류
계층적 군집화(Hierarchical)
Agglomerative
- 개별 포인트에서 시작 후 점점 크게 합쳐간다.
Divisive
- 하나의 큰 클러스터에서 시작 후 점점 작은 클러스터로 나눠간다.
Point Assignment
- 시작 시에 클러스터의 수를 정한 다음, 데이터들을 하나씩 클러스터에 배정시킨다.
하드, 소프트(Hard vs Soft)
- 하드 클러스터링에서 데이터는 하나의 클러스터에만 할당된다.
- 소프트 클러스터링에서 데이터는 여러 클러스터에 확률을 갖고 할당된다.
- 일반적으로 하드 클러스터링을 클러스터링이라고 칭한다.
유사성(Similarity)
- Euclidean
- 일반적으로 유클리디안이 많이 쓰인다.
- Cosine
- Jaccard
- Edit Distance
- etc
유클리디안(Euclidean)

1 | |
K-평균 군집화(K-means Clustering)
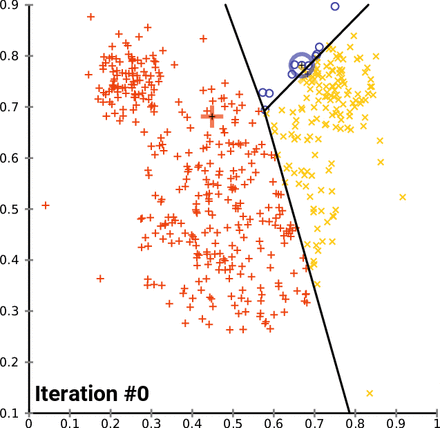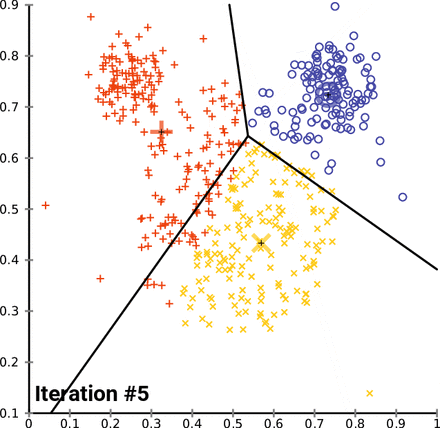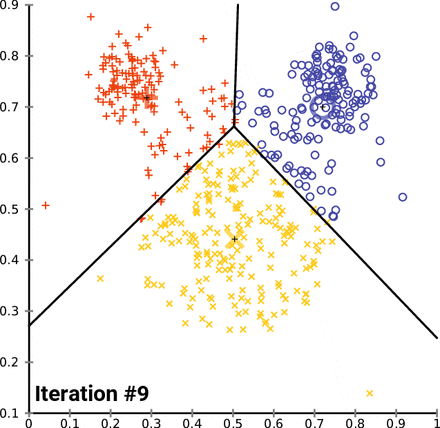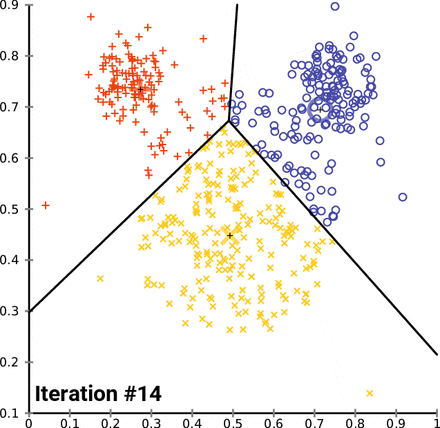
과정
- n차원의 데이터에 대해,
- 1) k개의 랜덤한 데이터를 클러스터의 중심점으로 설정한다.
- 2) 해당 클러스터에 근접해 있는 데이터를 클러스터로 할당한다.
- 3) 변경된 클러스터에 대해서 중심점을 새로 계산한다.
- 클러스터에 유의미한 변화가 없을 때 까지 2-3회 반복한다.
튜토리얼
1 | |

1 | |

중심점(Centroid) 계산
- K-평균은 중심점 베이스(Centroid-based) 알고리즘으로도 불린다.
- Centroid란, 주어진 클러스터 내부에 있는 모든 점들의 중심 부분에 위치한 가상의 점이다.
1 | |

랜덤한 포인트를 가상 클러스터의 중심점으로 지정
1 | |

그래프에 표기
1 | |

1 | |

1 | |

. . .
1 | |

1 | |
K를 결정하는 방법
- The Eyeball Method:사람의 주관적인 판단을 통해서 임의로 지정하는 방법이다.
- Metrics: 객관적인 지표를 설정하여, 최적화된 k를 선택하는 방법이다.
싸이킷런(Scikit-learn)
1 | |

1 | |

엘보우 메소드(Elbow methods)
1 | |

시간 복잡도

- K-평균 군집화 말고도 상당히 많은 클러스터링 알고리즘이 있으며, 각자 풀고자 하는 문제에 대해 최적화되어있다.
- 최적화된 문제를 제외한 다른 부분에 장점을 보이지 못한다는 단점도 있다.