아노바(ANOVA)

- 2개 이상 그룹의 평균에 차이가 있는지를 가설 검정하는 방법이다.
다중 비교 문제(Multiple Comparision)
- 2개 이상의 그룹을 비교할 때 각각 두 개 씩 여러번 T-Test를 하게 되면 에러가 날 확률이 커진다.
만약 m개 그룹에 대한 가설 검정이라면, $\bar{\alpha} = {1 - (1 - \alpha)}^{m}$ , $\bar{\alpha} \leq m \cdot {\alpha}$ 라는 것이 수학적으로 증명되어 있다.
- 여러 개를 하나하나 비교하는 것은 그룹 수가 늘어날 수록 에러도 커지기 때문에 한꺼번에 비교하는 방법이 필요하다.
변화(Variation)
- 여러 그룹 간 차이가 있는 지 확인하기 위해선 여러 그룹들이 하나의 분포에서 왔다라는 가정이 나오게 된다.
- 이를 위한 지표는 F-statistic이며 식은 아래와 같다.
- 위 F값이 높다는 것이 의미하는 바는,
- 분자(다른 그룹끼리는 분산)는 크고, 분모(전체 그룹의 분산)은 작아야 한다.
- 즉, 다른 그룹끼리의 분포가 다를것이다. 라는 가정이 붙는다.

공식 및 계산
$m$ = 전체 그룹 수, $n$ = 데이터 수
\[S_{w} = \sum_{i = 1}^{m} \sum_{j=1}^{n} (x_{ij} - x_{i.})^2\] \[x_{i.} = \sum_{j = 1}^{n} {x_{ij} / n}\] \[S_{b} = n \sum_{i=1}^m (x_{i.} - x_{..})^2\] \[x_{..} = {{\sum_{i=1}^m x_{i.} } \over {m}}\] \[F = { { S_{b}}/{(m-1)} \over S_{w} / (nm-m)}\] \[p( {F_{m-1, nm-m}} > F_{m-1, nm-m, \alpha}) = \alpha\]싸이파이(Scipy) 이용 구현
1 | |
많은 샘플(Many Samples)
큰 수의 법칙(Law of large numbers)
- 샘플의 데이터의 수가 커질 수록, 샘플의 통계치는 점점 모집단의 모수와 같아진다.
1 | |

- 사건을 무한히 반복할 때 일정한 사건이 일어나는 비율은 횟수를 거듭하면 할수록 일정한 값에 가까워진다.
중심 극한 정리(Central Limit Theorem, CLT)
- 샘플의 데이터의 수가 많아질 수록, 샘플의 평균은 정규분포에 근사한 형태로 나타난다.

1 | |

- 모집단의 분포에 상관없이 임의의 분포에서 추출된 표본들의 평균의 분포는 정규 분포를 이룬다.
- 중심 극한 정리로 인해 다음 두 가지가 가능해진다.
- 샘플 수가 30개 이상이라면, 모집단의 평균과 분산을 알아낼 수 있다.
- 모든 샘플들은 정규 분포로 나타낼 수 있으며, 정규 분포와 관련된 수학적 이론을 적용할 수 있게 된다.
신뢰도
- 통계에서 어떠한 값이 알맞은 모평균이라고 믿을 수 있는 정도이다.
- 즉, 신뢰도가 95% 라는 의미는 표본을 100번 뽑았을때 95번은 신뢰구간 내에 모집단의 평균이 포함된다.
신뢰구간의 설정 및 해석
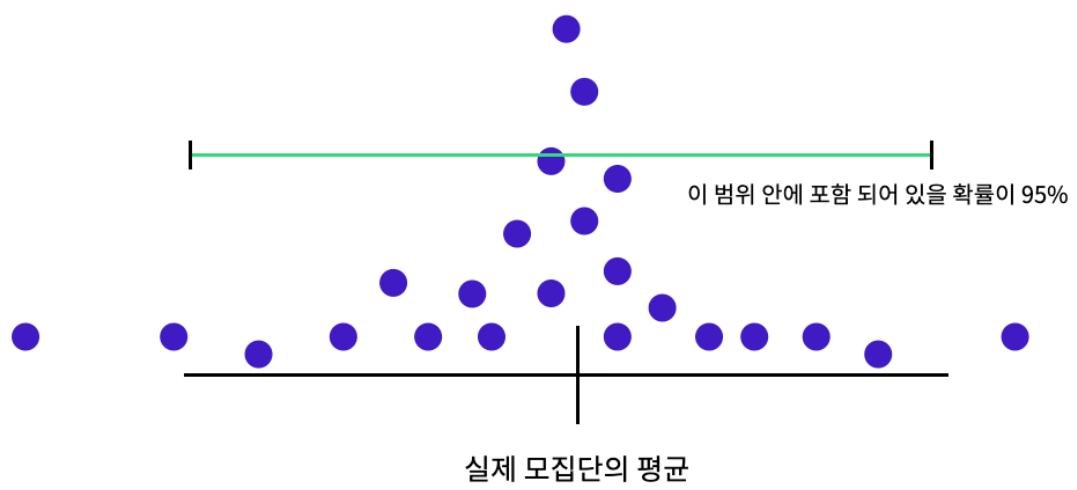
- 위 그림의 구간을 수학적으로 표현한 내용은 아래의 식과 같다.
- $\bar{x}$는
estimated mean, $ {t \cdot {s \over \sqrt{n} } }$는error라고 부른다.
싸이파이(scipy)에서의 신뢰 구간
1 | |
신뢰 구간 시각화
1 | |
