- 영상 처리를 위한 신경망
- Why Convolution
- 최근 Computer Vision의 대부분은 Convolution에 의존하고 있다고 해도 과언이 아니다.
- Weights을 공유하며, 특징을 추출하는데 이만한 방법론을 찾기 어렵기 때문이다.
- 사물인식 - Object Detection (YOLO) + RCNN(Fast, Faster, MASK RCNN)
- 포즈예측 - Pose Estimation (PoseNet)
- 윤곽분류 - Instance Segmentation (Detectron)
- YOLO를 사용하는 이유(찾아보기)
Convolution & Pooling
Convolution

- Convolution(합성곱)은 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱한 다음, 구간에 대해 적분하여 새로운 함수를 구하는 수학 연산자이다.
- 신경망 자체와 마찬가지로 CNN은 생물학, 특히 고양이의 시각 피질의 수용 영역(Receptive field)에서 영감을 받았다.
- 실제 뇌에서 시각 피질의 뉴런은 특정 영역, 모양, 색상, 방향 및 기타 일반적인 시각적 특징을 수용하도록 영역별로 전문화가 이루어진다.
- 어떤 의미에서인지 시스템의 구조 자체가 원시 시각 입력을 변환하여 특정 하위 집합을 처리하는 데 특화된 뉴런으로 보낸다.
- CNN은 Convolution을 적용하여 시각적 접근 방식을 모방한다.
- Convolution은 한 함수가 다른 함수를 수정하는 방법을 보여주는 세 번째 함수를 생성하는 두 함수에 대한 연산이다.
- Convolution에서는 교환성, 연관성, 분배성 등 다양한 수학적 속성이 있다.
- Convolution을 적용하면 입력의 Shape이 효과적으로 변환된다.
- Convolution이라는 용어는 세번째 공동함수(Weight Sharing)를 계산하는 프로세스와 이를 적용하는 프로세스를 모두 지칭하는 데 사용된다.
- 실제 동물의 시야에서 피질의 수용 영역으로의 매핑과 느슨하게 유사한 애플리케이션으로 생각하는 것이 유용하다.
수학적 이해
1D - Convolution

1 | |
2D - Convolution
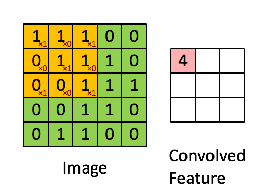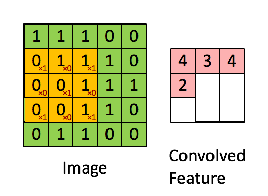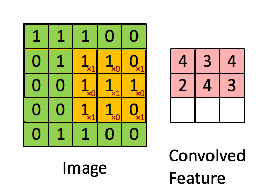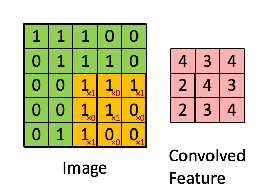
- 이미지의 노란색 부분으로 변하는 부분이 Convolution filter와 만나는 부분이다.
- 그렇게 연산되었을 때, 분홍색의 output 값을 얻을 수 있다.

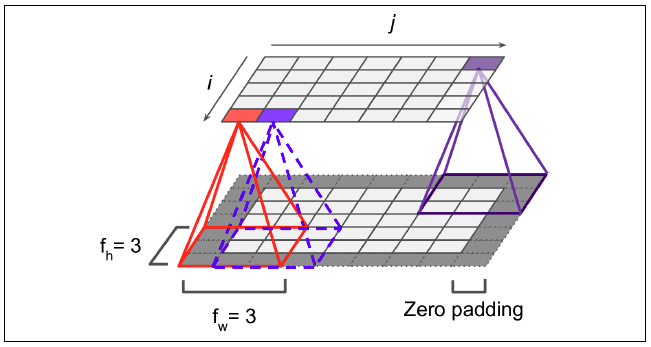
- Padding: 흰 색 pixel의 경우 실제 이미지가 있는 부분이고, 짙은 회색의 pixel은 feature map의 크기 조절과 데이터를 충분히 활용하기 위해 가장자리에 0을 더해준 것이다.
-
이런 방식을 zero-padding이라고 한다.
- Stride = 1
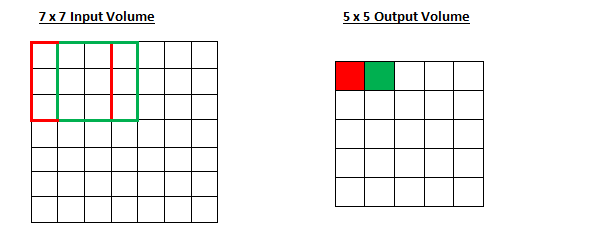
- Stride = 2
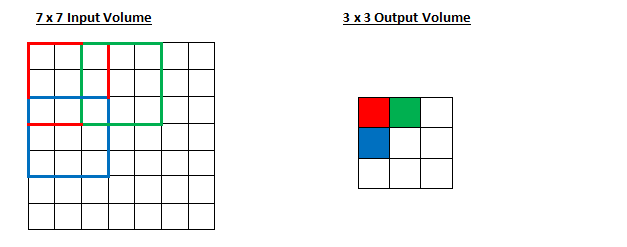
- Stride는 성큼성큼 걷는다는 표현의 단어 뜻을 가졌다.
- 한번에 얼마나 걸을 것인지 나타내는 의미이다.
- Stride가 1일 때는 한걸음씩, 2일 때는 두걸음씩 걸어가면서 연산을 한다.
- 주목해야할 것은 output의 사이즈가 달라진다는 것이다.
- Stride를 이용한 Convolution의 경우 pooling이 자동으로 되는 방식이다.
- 이후 GAN에서 해당 방식을 다루게 된다.
각종 용어
- Filter: 가중치(weights parameters)의 집합으로 이루어져 가장 작은 특징을 잡아내는 창이다.
Code
1 | |

1 | |

1 | |

Example
1 | |

1 | |

1 | |

1 | |

1 | |

1 | |

ImageNet으로 학습이 다 되었을 때 필터의 역할


Pooling Layer
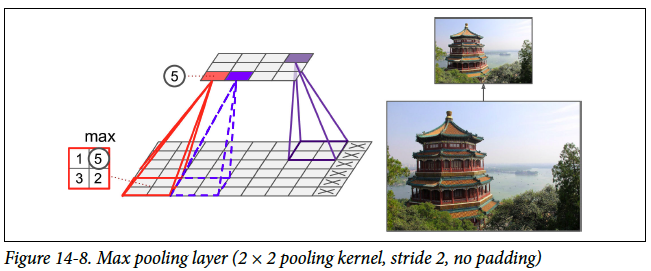
- 풀링 레이어를 사용하여 피처맵의 차원을 줄인다.
- 보통 Convolution을 적용한 이후 레이어를 풀링하여 점점 더 작은 피쳐맵을 얻는다.
- 이렇게 줄어든 피쳐를 이용하여 ANN형태의 신경망에 넣어 분류를 수행하게 된다.
Example
1 | |

1 | |
- CNN의 특징을 잡아내는 방식에 대해 살펴보았는데, 패치와 같은 형태로 특징을 잡아내기 때문에 얻어질 수 있는 장점을 간단히 생각해보면,
- Local Feature: 지역적 특징을 잡아 낸다.
- Weight Sharing
- Translation invariance: 어느정도 움직임이 있더라도 해석이 큰 무리가 없다.
CNN 분류기
전형적인 CNN Architecture

- CNN의 첫번째 단계는 Convolution이다.
- 특히 입력 이미지의 영역을 수신을 담당하는 뉴런에 매핑하는 변환이다.
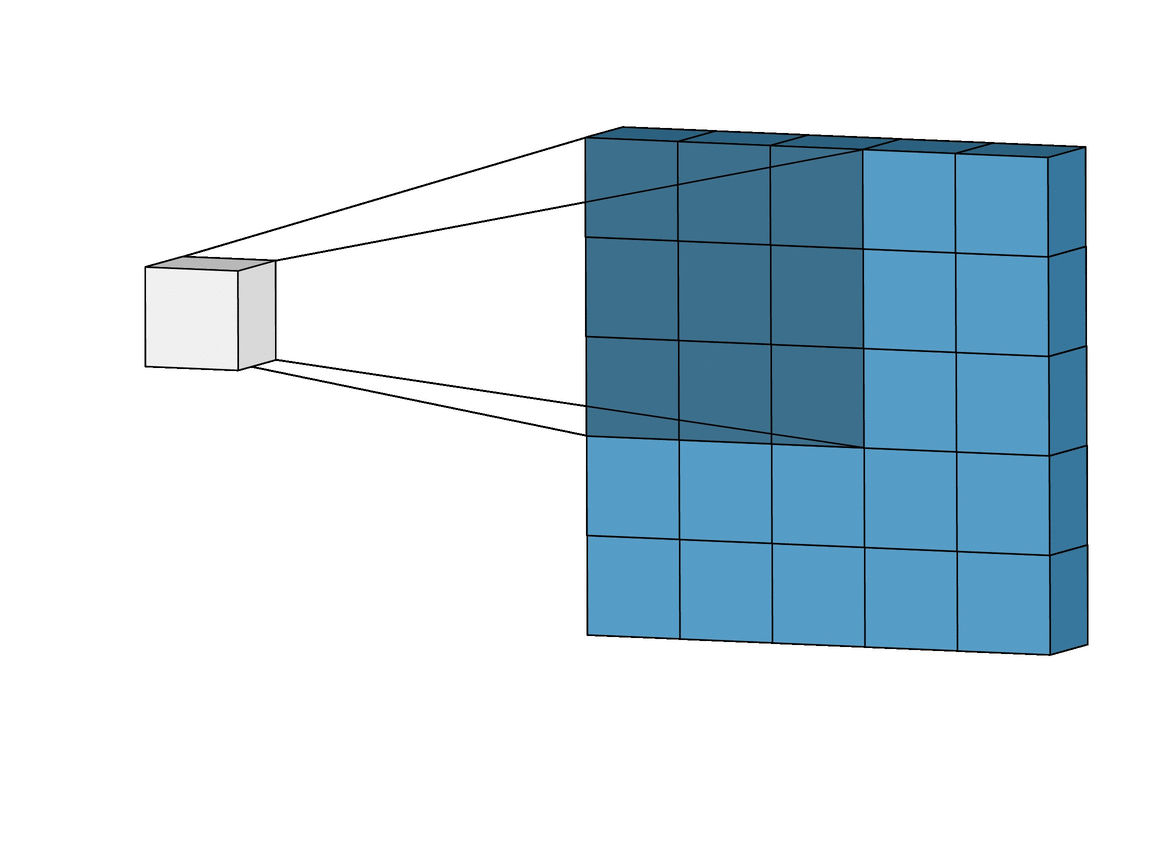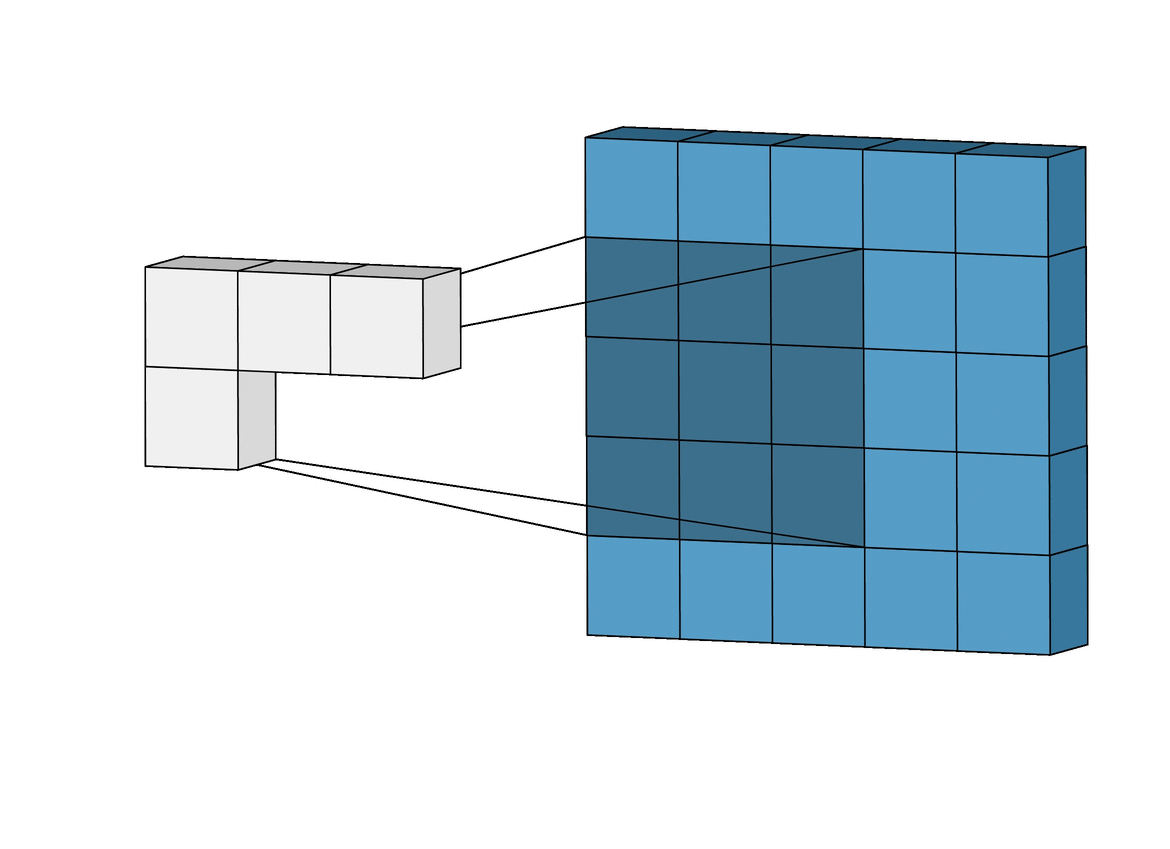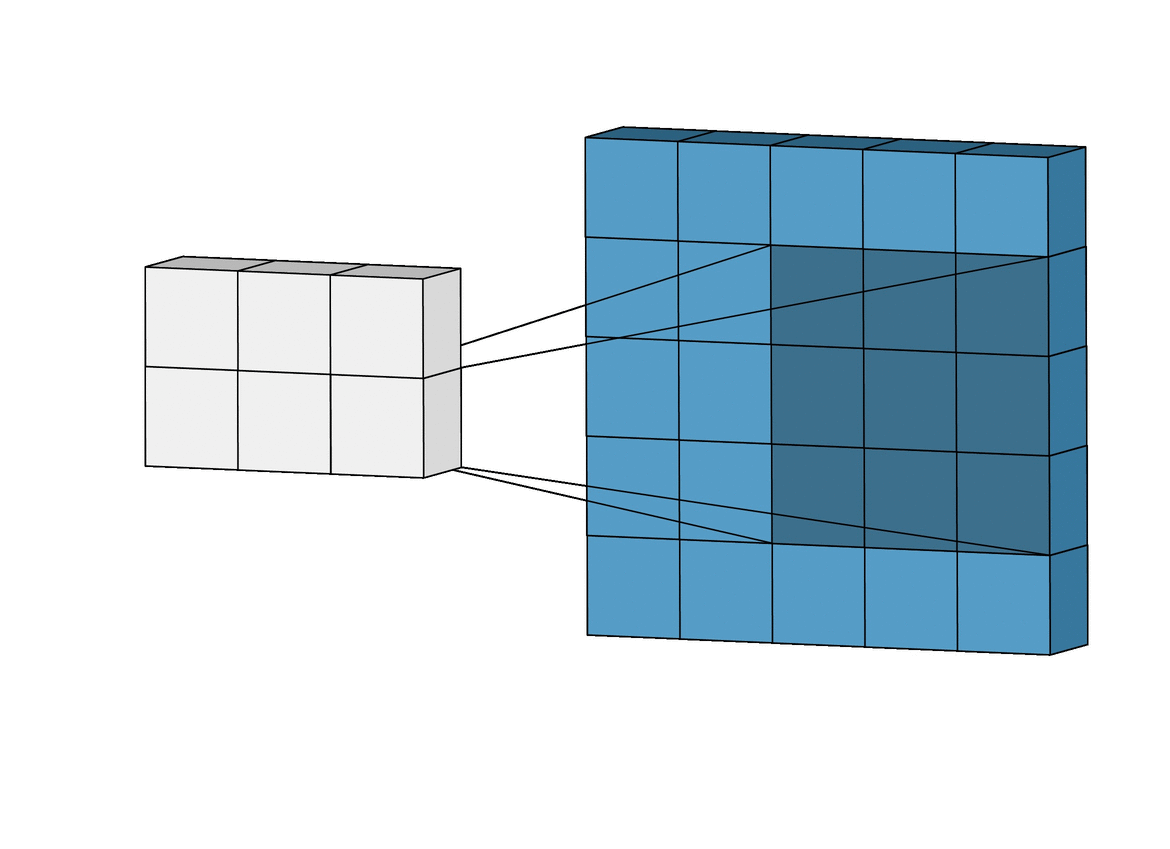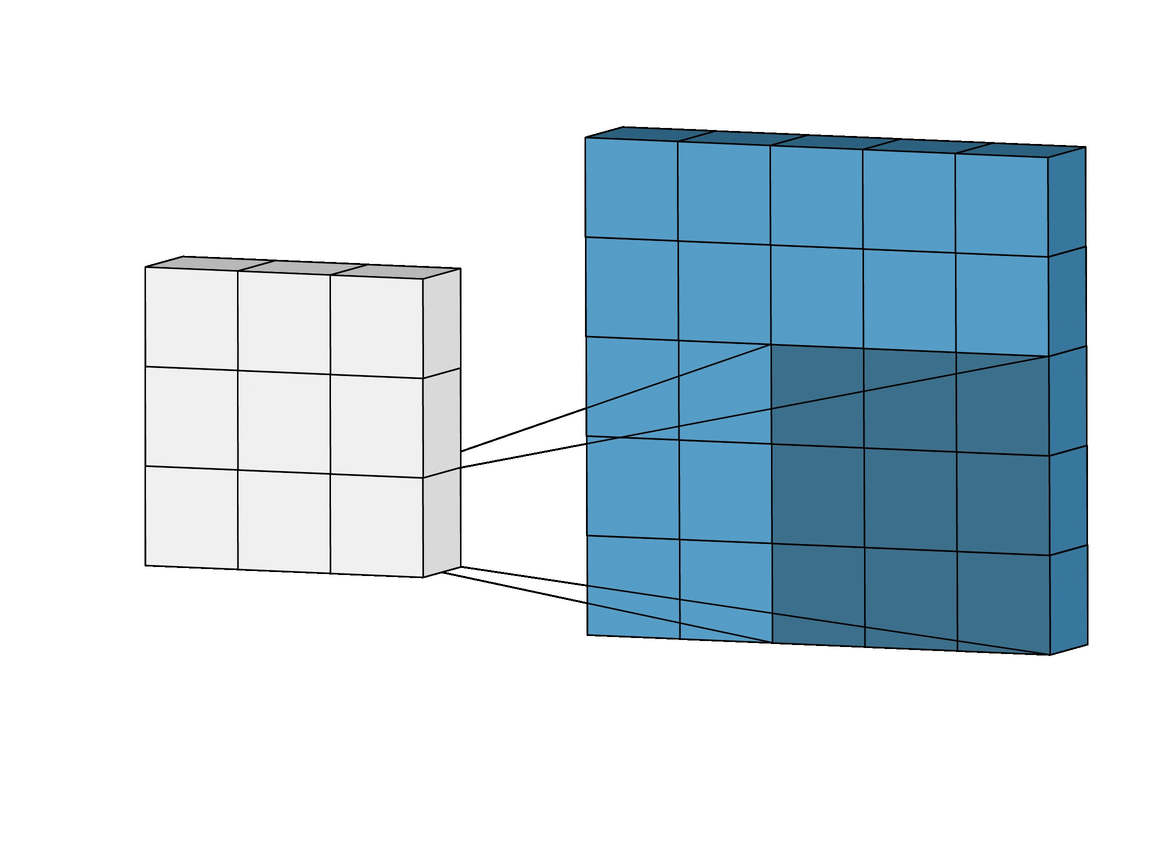
- Convolution Layer는 다음과 같이 시각화 할 수 있다.


- 빨간 박스는 원래 입력 이미지를 나타내고, 파란색은 해당하는 네트워크의 뉴런을 나타낸다.
- 속 안에 있는 작은 박스는 선택된 영역이 어떤 과정을 처리되는지 볼 수 있다.
- 여러가지 필터를 통과해서 하나의 이미지가 여러개의 특징으로 나눠진 것을 볼 수 있다.(Receptive field로 수영 영역을 나타낸다.)
- CNN은 여러 라운드의 Convolution, Pooling(필터를 통과하여 정보를 효과적으로 줄이는 디지털 신호 기술), 그리고 결국 완전 연결된 신경망과 출력 레이어를 가질 수 있다.
- CNN의 일반적인 출력 계층은 분류 또는 감지 문제를 지향한다.
A Convolution in Action
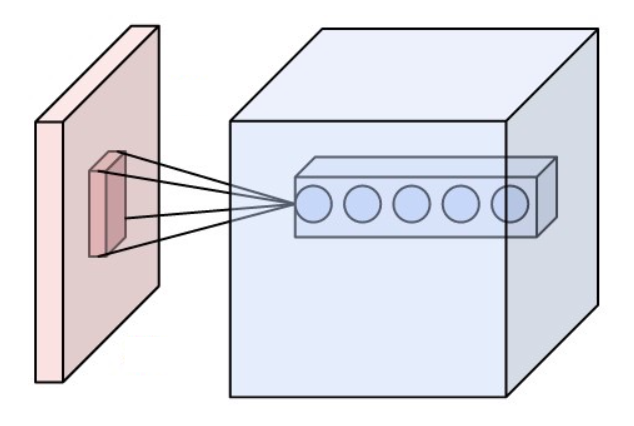
- CNN이 인기있는 이유
- 이전 이미지 학습 기술에 비해 이미지 전처리(자르게 / 센터링, 정규화 등)가 상대적으로 거의 필요하지 않다.
- 이와 관련하여 이미지 모든 종류의 일반적인 문제(이동, 조명 등)에 대해 견고하다.
- 실제로 최첨단 이미지 분류 CNN을 훈련하는 것은 계산적으로 중요하지 않다.
- 전이 학습을 통해 기성품을 만들어 사용할 수 있다.
다른 네트워크 표현 방식



실습 - Cifar 10
1 | |

1 | |
전이학습(Transfer Learning)
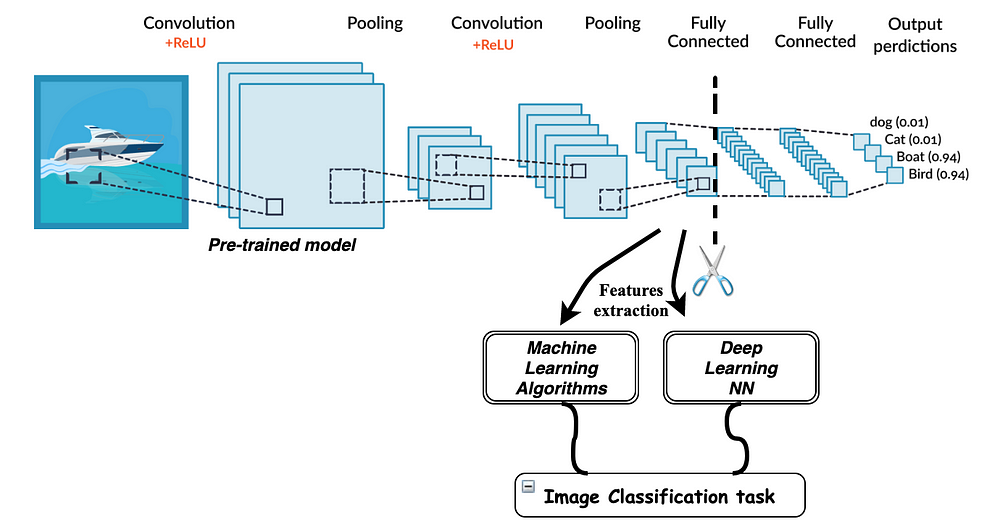
- 전이학습은 기존 데이터로 학습된 네트워크를 재사용 가능하도록 하는 라이브러리이다.
- 이를 통해 수천 시간의 GPU로 학습된 모델을 다운받아 내 작업에 활용할 수 있다.
- 학습되었다는 것은 가중치(Weights)와 편향(bias)이 포함되어 학습 된 모델의 일부를 재사용하기에 Transfer learning 이라고 표현한다.
- 일부만 사용해서 활용할 수도 있고, 전체를 다 재학습할 수도 있다.
- 교육 데이터를 적게 사용하고, 교육속도가 빠르며, 더 잘 일반화하는 모델을 가질 수 있다.
사용하는 방법
- 이전에 학습한 모델에서 파라미터를 포함한 레이어를 가져온다.
- 향후 교육 과정 중에 포함된 정보가 손상되지 않도록 해당 정보를 동결(freeze, 가중치를 업데이트 하지 않음)한다.
- 동결된 층 위에 새로운 층(학습 가능한 층)을 더한다.
- 출력층(output)의 수를 조절하여 새로운 데이터셋에서 원하는 예측방법(분류, 회귀 등)으로 전환하는 방법을 배울 수 있게 된다.
- 새로운 데이터셋에서 새로 추가한 계층만을 학습한다.
- 만약 기존 레이어를 동결하지 않으면, 학습된 레이어에서 가져온 weight까지 학습하게 된다.
- 위 경우 학습할 것이 많아지므로 시간이 오래걸린다.
- 중요한 벤치마크 모델을 적절하게 선택할 수 있다.
- 이미지 분류기 ResNet50를 기준으로 실습한다.
- ResNet은 CNN의 일종인데, 기존의 Squential 모델과 달리 skipped connection이 있는 모델이다.
- 이 연결을 통해 더 깊은 층을 만들더라도 학습이 가능해진다.
1 | |
Review
- Convolution은 필터 개념의 새로운 함수를 생성하여 연산하고 다음 레이어로 전달하는 가중치를 새롭게 만들어준다.
- Convolution은 커널(가중치 모음, 필터)은 CNN을 학습하는 과정에서 학습된다.
- Pooling은 데이터를 다운 샘플링하기 위해 피쳐 맵 영역의 최대 또는 평균을 사용하는 차원 감소 기술이다.
합성곱 층(Convolutional Layer)
- 합성곱 연산을 통해 이미지 특징을 추출하는 역할을 한다.
- kernal or filter라는 n * m 크기의 행렬로 높이(height) * 너비(width) 크기의 이미지를 처음부터 끝까지 겹치며 훑으면서 n * m 크기의 겹쳐지는 부분의 각 이미지와 커널의 원소 값을 곱해서 모두 더한 값을 출력하는 것이다.
- 커널은 일반적으로 3 * 3 or 5 * 5를 사용한다.
패딩(Padding)

- 합성곱 연산의 결과로 얻은 특성 맵은 입력보다 크기가 작아진다는 특징이 있다.
- 합성곱 층을 여러개 쌓았다면 최종적으로 얻은 특성 맵은 초기 입력보다 작아진 상태가 되어버린다.
- 합성곱 연산 이후에도 특성 맵의 크기가 입력의 크기와 동일하게 유지되도록 하고 싶을 때 Padding을 사용한다.
- Padding은 합성곱 연산을 하기 전에 입력의 가장자리에 지정된 개수의 폭만큼 행과 열을 추가해주는 것이다.
- 지정된 개수의 폭만큼 테두리를 추가한다.
- 주로 값을 0으로 채우는 Zero padding을 사용한다.
스트라이드(Stride)

- 필터를 적용하는 위치와 간격을 Stride라고 한다.
- 스트라이드가 2라면 필터를 적용하는 윈도우가 두 칸씩 이동한다
최대 풀링(Max Pooling)

- Pooling이란 세로 가로 방향의 공간을 줄이는 연산이다.
- 출력 데이터의 크기를 줄이거나 특정 데이터를 강조하기 위해 사용한다.
- Max pooling은 최댓값을 구하는 연산으로, 영역에서 가장 큰 원소를 하나 꺼낸다.
- 풀링의 윈도우 크기와 스트라이드는 같은 값으로 설정하는 것이 보통이다.
전이 학습(Transfer Learning)
- 이미지넷이 제공하는 거대한 데이터셋으로 학습한 가중치 값들은 실제 제품에 활용해도 효과적이고 많이들 그렇게 이용한다.
- 학습된 가중치(혹은 그 일부)를 다른 신경망에 복사한 다음, 그 상태로 재학습을 수행한다.
Skipped Connection

- 층을 깊게 하는 것이 성능 향상에 중요하지만, 층이 지나치게 깊으면 학습이 잘 되지 않고 오히려 성능이 떨어지는 경우가 많다.
- ResNet에서는 그런 문제를 해결하기 위해 Skipped connection을 도입했다.
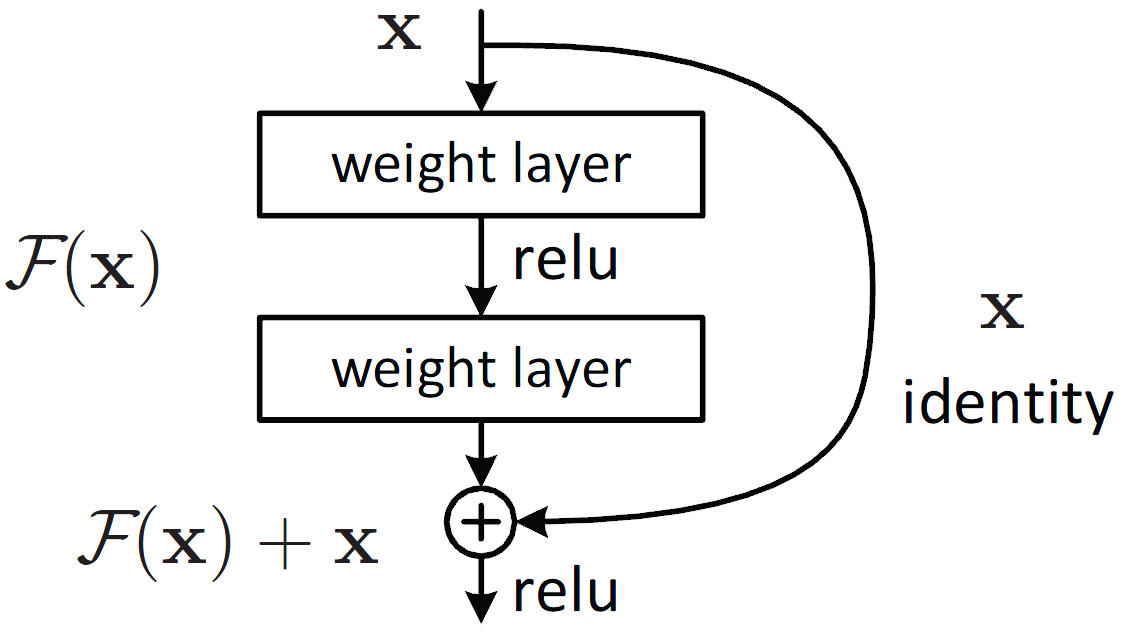
- Skipped connection은 입력 데이터를 합성곱 계층을 건너뛰어 출력에 바로 더하는 구조를 말한다.
- 위 그림에서 입력 x를 연속한 두 합성곱 계층을 건너뛰어 출력에 바로 연결한다.
- 이 단축 경로가 없었다면 두 합성곱 계층의 출력이 F(x)가 되나, 스킵 연결로 인해 F(x) + x 가 된다.
- 스킵 연결은 층이 깊어져도 학습을 효율적으로 할 수 있도록 해주는데, 이는 역전파 때 스킵 연결이 신호 감쇠를 막아주기 때문이다.
- 스킵 연결은 데이터를 그대로 흘리는 것으로, 역전파 때도 상류의 기울기를 그대로 하류로 보낸다.
- 여기서 핵심은 상류의 기울기에 아무런 수정도 가하지 않고 그대로 흘린다는 것이다.
- 스킵 연결로 기울기가 작아지거나 지나치게 커질 걱정 없이 앞 층에 의미 있는 기울기가 전해지리라 기대할 수 있다.
- 층을 깊게 할수록 기울기가 작아지는 소실 문제를 이 스킵 연결이 줄여주는 것이다.
Reference
- Keras CNN Tutorial
- Tensorflow + Keras
- Convolution Wiki
- Keras Conv2D: Working with CNN 2D Convolutions in Keras
- Intuitively Understanding Convolutions for Deep Learning
- A Beginner’s Guide to Understanding Convolutional Neural Networks Part 2
- Keras Transfer Learning Tutorial
- 밑바닥부터 시작하는 딥러닝
- 딥 러닝을 이용한 자연어 처리 입문: 합성곱 신경망
- Skip connection 정리
- Convolutional Neural Network (CNN)