- 분포 표현(Distributed Representation): 단어 분포를 중심으로 단어를 벡터화한다.
- 대표적 방법 중 하나는 Word2Vec(워드투벡터)이다.
- [딥러닝 자연어처리]Word2Vec
- 원핫인코딩은 유사도가 없다.
- Embedding
- 유사도를 구할 수 있다.
- 저차원이다.

Distributed Representation
- 단어 자체를 벡터화하는 방법이다.
- Word2Vec, fastText는 벡터로 표현하고자 하는 타겟 단어(Target word)가 해당 단어 주변 단어에 의해 결정된다.
- 단어 벡터를 이렇게 정하는 이유는 분포 가설(Distribution hypothesis) 때문이다.
- ‘비슷한 위치에서 등장하는 단어는 비슷한 의미를 가진다’
- 비슷한 의미를 지닌 단어는 주변 단어 분포도 비슷하다.
- 분포 가설에 기반하여 주변 단어 분포를 기준으로 단어의 벡터 표현이 결정되기 때문에 분산 표현(Distirbuted representation)이라고 부른다.
One hot Encoding
- 단어를 벡터화하고자 할 때 선택할 수 있는 쉬운 방법이다.
- 치명적인 단점이 단어 간 유사도를 구할 수 없다는 점이다.
- 단어 간 유사도를 구할 때 코사인 유사도가 자주 사용된다.
- 코사인 유사도:
- 원핫인코딩을 사용한 두 벡터의 내적은 항상 0이므로 어떤 두 단어를 골라 코사인 유사도를 구하더라도 그 값은 0이 된다.
- 이 때문에 어떤 단어를 골라도 두 단어 사이의 관계를 전혀 알 수 없게 된다.
Embedding
- 원핫인코딩의 단점을 해결하기 위해 등장했다.
- 단어를 고정 길이의 벡터, 즉 차원이 일정한 벡터로 나타내기 때문에 ‘Embedding’이라는 이름이 붙었다.
- 벡터 내의 각 요소가 연속적인 값을 가지게 된다.
- 가장 널리 알려진 방법은 Word2Vec이다.
Word2Vec
- 단어를 벡터로 나타내는 방법으로 가장 많이 사용된다.
- 특정 단어 양 옆에 있는 두 단어의 관계를 활용하기 때문에 분포 가설을 잘 반영하고 있다.
- CBoW와 Skip-gram의 2가지 방법이 있다.
CBoW & Skip-gram
- 차이
- 주변 단어에 대한 정보를 기반으로 중심 단어의 정보를 예측하는 모델 ▶️ CBoW(Continuous Bag-of-Words)
- 중심 단어의 정보를 기반으로 주변 단어의 정보를 예측하는 모델 ▶️ Skip-gram

- 예시
- <별 헤는="" 밤="">의 일부분에 형태소 분석기 적용하여 토큰화
“… 어머님 나 는 별 하나 에 아름다운 말 한마디 씩 불러 봅니다 …”
CBoW를 사용하면 표시된 단어 정보를 바탕으로 아래의 [ —- ] 에 들어갈 단어를 예측하는 과정으로 학습이 진행된다.
“… 나 는 [ – ] 하나 에 … “
“… 는 별 [ —- ] 에 아름다운 …”
“… 별 하나 [ – ] 아름다운 말 …”
“… 하나 에 [ ——– ] 말 한마디 …”
Skip-gram을 사용하면 표시된 단어 정보를 바탕으로 다음의 [ —- ] 에 들어갈 단어를 예측하는 과정으로 학습이 진행된다.
“… [ – ] [ – ] 별 [ —- ] [ – ] …”
“… [ – ] [ – ] 하나 [ – ] [ ——– ] …”
“… [ – ] [ —- ] 에 [ ——– ] [ – ] …”
“… [ —- ] [ – ] 아름다운 [ – ] [ —— ] …”
- 더 많은 정보를 바탕으로 특정 단어를 예측하기 때문에 CBoW의 성능이 더 좋을 것으로 생각할 수 있지만, 역전파 관점에서 보면 Skip-gram에서 훨씬 더 많은 학습이 일어나기 때문에 Skip-gram의 성능이 조금 더 좋게 나타난다.(물론 계산량이 많기 때문에 리소스도 더 크다.)
구조
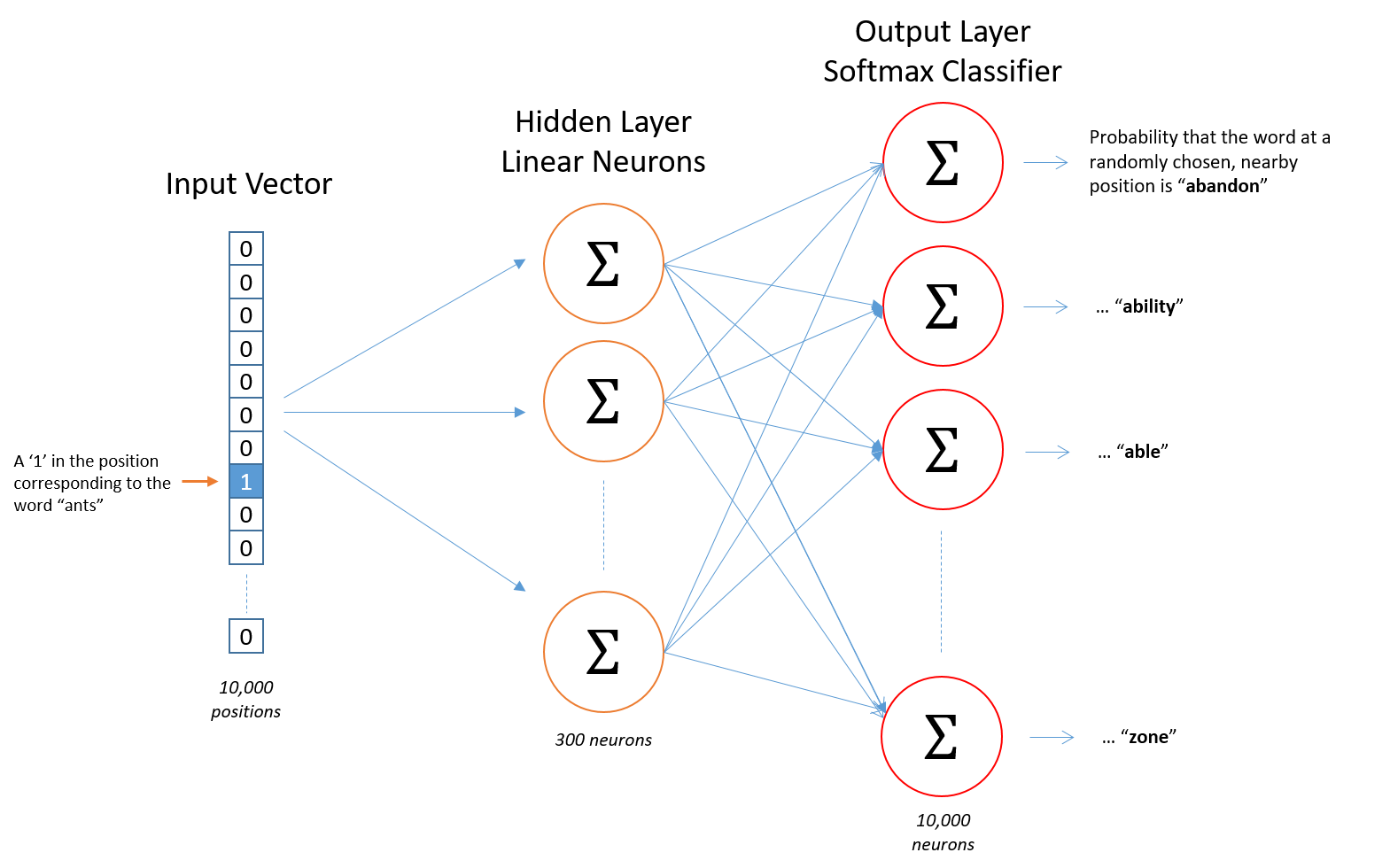
- Skip-gram 기준 Word2Vec 구조
- 입력: Word2Vec의 입력은 원핫인코딩된 단어 벡터
- 은닉: 임베딩 벡터의 차원수 만큼의 노드로 구성된 은닉층이 1개인 신경망
- 출력: 단어 개수 만큼의 노드로 이루어져 있으며 활성화 함수로 소프트맥스를 사용
- 논문에서는 총 10,000개의 단어에 대해서 300차원의 임베딩 벡터를 구했기 때문에 신경망 구조가 아래와 같다.
학습 데이터 디자인
- 효율적인 Word2Vec 학습을 위해 학습데이터를 잘 구성해야 한다.
- Window 사이즈가 2인 Word2Vec 이므로 중심 단어 옆에 있는 2개 단어에 대해 단어쌍을 구성한다.
- 만약 ‘“The tortoise jumped into the lake” 라는 문장에 대해 단어쌍을 구성한다면, 윈도우 크기가 2인 경우 다음과 같이 Skip-gram을 학습하기 위한 데이터 쌍을 구축할 수 있다.
- 중심 단어 : The, 주변 문맥 단어 : tortoise, jumped
- 학습 샘플: (the, tortoise), (the, jumped)
- 중심 단어 : tortoise, 주변 문맥 단어 : the, jumped, into
- 학습 샘플: (tortoise, the), (tortoise, jumped), (tortoise, into)
- 중심 단어 : jumped, 주변 문맥 단어 : the, tortoise, into, the
- 학습 샘플: (jumped, the), (jumped, tortoise), (jumped, into), (jumped, the)
- 중심 단어 : into, 주변 문맥 단어 : tortoise, jumped, the, lake
- 학습 샘플: (into, tortoise), (into, jumped), (into, the), (into, lake)
- 중심 단어 : The, 주변 문맥 단어 : tortoise, jumped
- 다음과 같은 데이터쌍이 만들어 진다.
| 중심단어 | 문맥단어 |
| the | tortoise |
| the | jumped |
| tortoise | the |
| tortoise | jumped |
| tortoise | into |
| jumped | the |
| jumped | tortoise |
| jumped | into |
| jumped | the |
| into | tortoise |
| into | jumped |
| into | the |
| into | lake |
| … | … |
결과
- 학습이 모두 끝나면 10000개의 단어에 대해 300차원의 임베딩 벡터가 생성된다.
- 임베딩 벡터의 차원을 조절하고 싶다면 은닉층의 노드 수를 줄이거나 늘릴 수 있다.
- 아래 그림은 신경망 내부에 있는 10000*300 크기의 가중치 행렬에 의해 10000개 단어에 대한 300 차원의 벡터가 생성되는 모습을 나타낸 이미지이다.

효율을 높이기 위한 기법
Nagative-sampling
\[p(w_i) = \frac{f(w_i)^{3/4}}{\sum ^{10000}_{j=1} f(w_j)^{3/4}}\]- Nagative 값을 샘플링하는 것이다.
- 무관한 단어들에 대해 weight를 업데이트하지 않아도 된다.
- n개의 negative 값을 선택하고 이 값들에 대해서만 positive 값과 함게 학습한다.
- 논문에서 negative 갯수인 n은 작은 데이터에서는 5-20, 큰 데이터에서는 2-5라고 제시하였다.
Subsampling
\[P(w_i) (\sqrt{ \frac{z(w_i)}{0.001}}+1) \frac{0.001}{z(w_i)}\]- 텍스트 자체가 가진 문제를 다룬 방법이다.
-
자주 등장하지만 별 쓸모는 없는 단어를 다룬다.
- 결과적으로 Skip-gram 모델을 통해 10000개의 단어에 대한 임베딩 벡터를 얻었다.
- 이렇게 얻은 임베딩 벡터는 문장 간 관련도 계산, 문서 분류같은 작업에 사용할 수 있다.
임베딩 벡터 시각화
- 임베딩 벡터는 단어간의 의미적, 문법적 관계를 잘 나타낸다.
-
man - woman사이의 관계와king - queen사이의 관계가 매우 유사하다.
생성된 임베딩 벡터가 단어의 의미적(Semantic) 관계를 잘 표현한다. -
walking - walked사이의 관계와swimming - swam사이의 관계가 매우 유사하다.
생성된 임베딩 벡터가 단어의 문법적(혹은 구조적, Syntactic)인 관계도 잘 표현한다. - 고유명사에 대해서도 나라 - 수도 와 같은 관계를 잘 나타내고 있다.
실습
gensim 패키지
1 | |
fastText
- fastText는 Word2Vec 방식에 철자(Character) 기반의 임베딩 방식을 더해준 새로운 임베딩 방식이다.
OOV(Out of Vocabulary) 문제
- 세상 모든 단어가 들어있는 말뭉치를 구하는 것은 불가능하다.
- Word2Vec은 말뭉치에 등장하지 않은 단어에 대해 임베딩 벡터를 만들지 못한다는 단점이 있다.
- 기존 말뭉치에 등장하지 않는 단어가 등장하는 문제를 OOV 문제라고 한다.
- 또한 적게 등장하는 단어에 대해 학습이 적게 일어나기 때문에 적절한 임베딩 벡터를 생성해내지 못한다는 것도 Word2Vec의 단점이다.
철자 단위 임베딩(Character level Embedding)
- fastText는 철자(Character) 수준의 임베딩을 보조 정보로 사용함으로써 OOV 문제를 해결했다.
- 모델이 학습하지 못한 단어더라도 잘 쪼개고 보면 말뭉치에서 등장했던 단어를 통해 유추해 볼 수 있다는 아이디어에서 출발했다.
- fastText가 Character-level(철자 단위) 임베딩을 적용하는 법: Character n-gram
- 3-6개로 묶은 Character 정보(3-6 grams) 단위를 사용한다.
- 묶기 이전에 모델이 접두사와 접미사를 인식할 수 있도록 해당 단어 앞뒤로 <, >를 붙여준다.

| word | Length(n) | Character n-grams |
| eating | 3 | <ea, eat, ati, tin, ing, ng> |
| eating | 4 | <eat, eati, atin, ting, ing> |
| eating | 5 | <eati, eatin, ating, ting> |
| eating | 6 | <eatin, eating, ating> |
- 총 18개의 Character-level n-gram을 얻을 수 있다.
- 알고리즘이 매우 효율적으로 구성되어 있기 때문에 시간상으로 Word2Vec과 엄청난 차이가 있지는 않다.
적용
1 | |
시각화


실습
gensim 패키지
1 | |
- 단어 뜻만 보면 fight가 나와야 하지만, 뜬금없기 noon이 등장했다.
- fastText 임베딩 벡터는 단어의 의미보다 결과 쪽에 조금 더 비중을 두고 있다.
문장 분류 수행
- 가장 간단한 것은 문장에 있는 단어 벡터를 모두 더한 후 평균내어 구하는 방법이다.
- 간단한 문제에 대해 좋은 성능을 보여서 baseline 모델로 많이 사용된다.
1 | |
Review
- 원-핫 인코딩이란?
- 원-핫 인코딩 단점은?
- 분포 기반의 표현, 임베딩이란?
- 분포 가설이란?
- 임베딩 벡터는 특징은?
- CBoW와 Skip-gram의 차이는 무엇이며, 어떤 방법이 성능이 더 좋을까? 성능이 더 좋은 방법의 단점은?
- Word2Vec의 임베딩 벡터를 시각화한 결과가 어떤 특징을 가지는지?
- Word2Vec의 단점은?
- OOV 문제란?
- 철자(Character) 단위 임베딩 방법의 장점은?
분포 가설(Distributed Hypothesis)
- 비슷한 위치에서 등장하는 단어는 비슷한 의미를 가진다.
Word2Vec
- 원핫인코딩은 단어 간 유사도를 계산을 할 수 없다는 단점이 있는데, 유사도를 반영할 수 있도록 단어의 의미를 벡터화 하는 방법이다.
- 주변에 있는 단어로 중간에 있는 단어를 예측하는 CBoW와 중간에 있는 단어로 주변에 있는 단어를 예측하는 Skip-Gram 방식이 있다.
- 모르는 단어(OOV)는 분석할 수 없다.
fastText
- Word2Vec은 단어를 쪼갤 수 없는 단위로 생각한다면, festText는 하나의 단어 안에도 여러 단어가 존재하는 것으로 간주한다.
- 글자 단위의 n-gram의 구성으로 취급하며, n의 수에 따라 단어가 얼마나 분리되는지 결정된다.
- 모르는 단어(OOV)도 분석할 수 있다.
GloVe
- 임베딩된 두 단어벡터의 내적이 말뭉치 전체에서의 동시 등장확률 로그값이 되도록 목적함수를 정의하여 임베딩 된 단어벡터 간 유사도 측정을 수월하게 하면서도 말뭉치 전체의 통계정보를 반영하기위해 나온 방법이다.