

(필기노트 제공 by Crystal Yim in CS AIB 5th)
신경망 구조(recap.)
- 신경망의 학습: 적절한 가중치를 찾아가는 과정
- HOW?
- Gradient descent, Backpropagation!
- 경사 하강법에 필요한 Gradient 계산을 역전파 알고리즘을 통해 구한다.

- 신경망에는 3개의 Layer가 존재한다.
- 각 층은 Node로 구성되어 있으며, 각 노드는 Weight, Bias로 연결되어 있다.
- 순전파: 입력층에서 입력된 신호가 은닉층의 연산을 거쳐 출력층에서 값을 내보내는 과정
- 입력층으로부터 신호를 전달
- 입력된 데이터를 가중치 및 편향과 연산한 뒤 더해준다.(가중합, Weighted Sum)
- 가중합을 통해 구해진 값은 Activation func을 통해 다음 층으로 전달
- 특정 층에 입력되는 데이터의 특성의 $n$개인 경우 수식으로 나타낸다면,(Sigmoid)
신경망 학습 알고리즘 요약
- 데이터와 목적에 맞게 신경망 구조 설계
- Input node: 데이터 Feature 수
- Output node: 문제에 따라 다르게 설정
- Hidden과 node 수 결정
- Weight Random 초기화
- 순전파를 통해 출력값($h_{\theta}(x^{(i)})$)을 모든 입력 데이터($x^{(i)}$)에 대해 계산
- Cost func($J(\theta)$) 계산
- 역전파를 통해 각 가중치에 대해 편미분 값($\partial J(\theta)/\partial\theta_{jk}^{l}$)을 계산
- 경사하강법을 사용하여 비용함수($J(\theta)$)를 최소화하는 방향으로 가중치를 갱신
- 중지 기준을 충족하거나 비용함수를 최소화 할 때까지 2-5단계 반복(iteration)
Cost Func or Loss Func
- 신경망은 Loss func를 최소화하는 방향으로 weight을 갱신
- Loss func을 잘 정의해주어야 weight이 제대로 갱신
- 입력 데이터를 신경망에 넣어 순전파를 거치면 마지막 출력층을 통과한 값이 도출
- 출력된 값과 그 데이터의 타겟값을 손실함수에 넣어 손실(Loss or Error)를 계산
- 한 데이터 포인트에서의 손실을 Loss라고 하며, 전체 데이터셋의 Loss를 합한 개념을 Cost라고 한다.
- 대표적 손실함수: MSE, Cross-Entropy
- 신경망 학습에는 머신러닝 알고리즘보다 많은 훈련 데이터가 필요
- 그에 따라 시간도 오래 걸리고 최적화를 위해 더 많은 Hyperparameter tuning을 해주어야한다.
- 복잡한 신경망을 훈련하기 위해 특별한 방법이 바로 Backpropagation Algorithm
Backpropagation
- Backwards Propagation of Errors의 줄임말
- 순전파와는 반대 방향으로 Loss of Error 정보를 전달해주는 역할
- 순전파가 입력 신호 정보를 입력층부터 출력층까지 전달하여 값을 출력하는 알고리즘이라면,
- 역전파는 구해진 손실 정보를 출력층부터 입력층까지 전달하여 각 가중치를 얼마나 업데이트 해야할지를 결정하는 알고리즘
- 매 iteration 마다 구해진 Loss를 줄이는 방향으로 가중치 업데이트
- 손실을 줄이는 방향을 결정하는 것이 Gradient Descent
- GD와 BP를 이해하기 위해서는 미분법에 대한 이해가 필요하다.

Exemple
- 공부시간, 수면시간을 특성으로 하고 시험 점수를 레이블로 하는 회귀 예제
- $x_1$ 은
공부시간을 나타내고 $x_2$ 는수면시간
1 | |
1 | |
- 행렬의 곱셈 연산
$A_{l \times m}, B_{m \times n}$ 두 행렬을 곱할 때 $\Rightarrow (AB)_{l \times n}$
결과값으로 나오는 행렬의 shape은 $\big($$l$ $\times$ $m$$\big)$ $\cdot$ $\big($ $m$ $\times$ $n$ $\big)$ = $l$ $\times$ $n$ 행렬의 형태로 연산

1 | |
분석
- 에러가 높게 나온 이유: 예측값이 정확하지 않기 때문
- 예측값이 정확하지 않은 이유: 임의로 지정하였던 가중치 값이 작거나, 첫번째 층의 출력값이 작기 때문
- 첫번재 층의 출력값이 작은 이유: 입력 데이터는 변하지 않는 값이므로 첫번째 층의 가중치 값이 작기 때문
- 예측값을 증가시키기 위한 방법: 첫번째 층과 두번째 층의 가중치를 증가시키는 것
1 | |
HOW?
- Error를 줄이기 위해서 어떻게 해야할까?
- Cost func $J$의 Gradient가 작아지는 방향으로 업데이트하면 손실함수의 값을 줄일 수 있다.
- 매 iteration마다 해당 가중치에서의 Cost func의 도함수(미분한 함수)를 계산하여 경사가 작아지도록 가중치를 변경한다.

- 위의 신경망은 총 9개의 가중치를 가졌다.
- 첫 번째 층에는 6개(
w1), 두 번째 층에는 3개(w2) - 해당 신경망의 비용 함수는 9차원 공간상의 함수$(J)$
- 비용 함수 $J$를 수식으로 나타내면,

Convex/Concave func과 Local Optima
- 경사 하강법을 통해 최저점을 찾는 메커니즘은 Convex func에서만 잘 동작
- 실제 손실 함수는 위 그림처럼 Convex, Concave가 공존
- So, Global Optima를 찾지 못하고 Local Optima에 빠질 수 있다.
- 그래서 또 방지하는 법이 있지.
Update weight: BP

1 | |
- 수식을 통해 위 코드를 ARABOZA
- 손실(Error) : $E$
- 출력층 활성화 함수의 출력값(
activated_output) : $A_O$ - 출력층 활성화 함수의 입력값(=가중합,
output_sum) : $S_O$ - 은닉층 활성화 함수의 출력값(
activated_hidden) : $A_H$ - 은닉층 활성화 함수의 입력값(=가중합,
hidden_sum) : $S_H$ - $w_2$(=출력층과 은닉층 사이의 가중치) 에 대한 미분
- $w_1$(=은닉층과 입력층 사이의 가중치) 에 대한 미분
역전파 신경망 클래스 학습
1 | |
- 에러(Error,
o_error)와 출력층 활성화 함수를 미분한 함수(sigmoidPrime)를 통해서 출력층의 경사(o_delta) 확인 self.o_delta = self.o_error * self.sigmoidPrime(self.output_sum)
1 | |
- Hidden Layer Error
- 이전 단계에서 구했던 출력층의 경사(
o_delta)와 출력층의 가중치(w2)를 통해서 은닉층이 받는 손실(z2_error) 계산 self.z2_error = self.o_delta.dot(self.w2.T)
1 | |
- Hidden Layer Gradient
-
은닉층 에러(
z2_error)와 은닉층 활성화 함수를 미분한 함수(sigmoidPrime)를 통해서 은닉층의 경사(z2_delta)를 계산 self.z2_delta = self.z2_error * self.sigmoidPrime(self.activated_hidden)
1 | |
Gradient Descent 적용
- 은닉층 가중치(
w1)를 업데이트
X에 대해 Transpose 해주는 이유

(필기노트 제공 by Crystal Yim in CS AIB 5th)
1 | |
- 출력층 가중치(
w2)를 업데이트 합니다.
1 | |
신경망 학습
1 | |
- 출력 결과로 반복수가 1-5회일 때의 에러와 이후 1000회 마다의 에러를 볼 수 있다.
- 점점 에러가 줄어드는 경향성을 확인할 수 있다.
Optimizer
- 지역 최적점에 빠지게 되는 문제를 방지하기 위한 여러가지 방법 중 하나가 Optimizer
- Optimizer: 경사를 내려가는 방법을 결정

Stochastic Gradient Descent

- 확률적 경사 하강법과 미니 배치(Mini-batch) 경사 하강법
- 전체 데이터에서 하나의 데이터를 뽑아 신경망에 입력한 후 손실 계산한 후 손실 정보를 역전파하여 신경망의 가중치를 업데이트
- 장점: 확률적 경사하강법은 1개의 데이터만 사용하여 손실을 계산하기 때문에 가중치를 빠르게 업데이트 할 수 있다.
- 단점: 1개의 데이터만 보기 때문에 학습 과정에서 불안정한 경사 하강을 보인다.

- 두 방법을 적당히 융화한 Mini batch Gradient Descent가 등장
- N개의 데이터로 미니 배치를 구성하여 해당 미니 배치를 신경망에 입력한 후 이 결과를 바탕으로 가중치 업데이트
- 일반적으로 미니 배치 경사 하강법을 많이 사용

다양한 Optimizer
- SGD
- SGD 변형: Momentum, RMSProp, Adam
- Newton’s method 등의 2차 최적화 알고리즘 기반 방법: BFGS
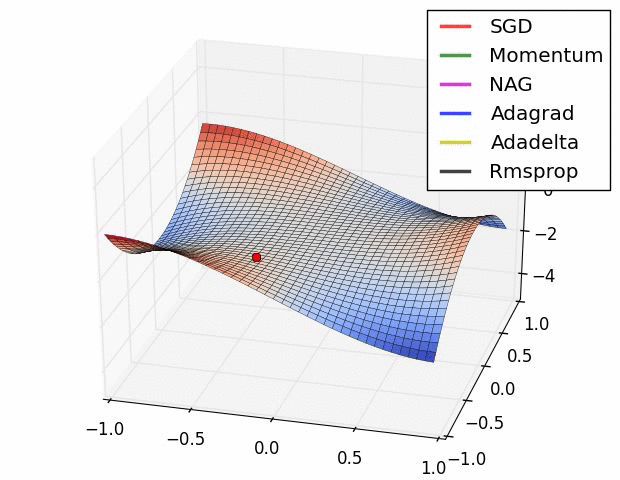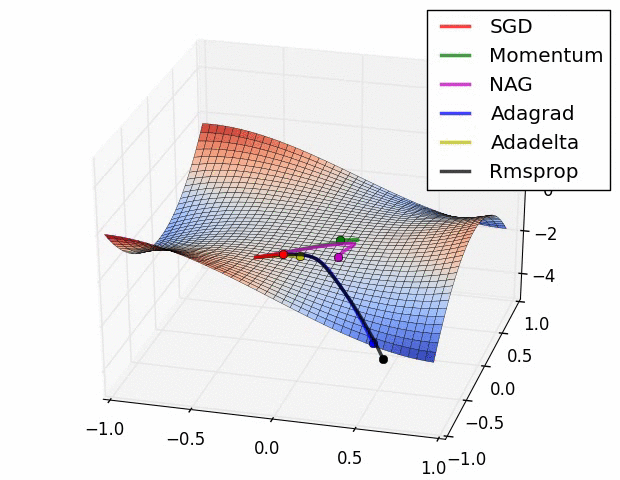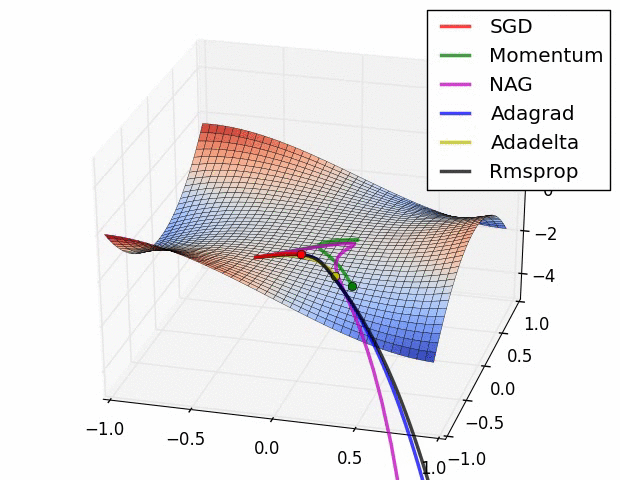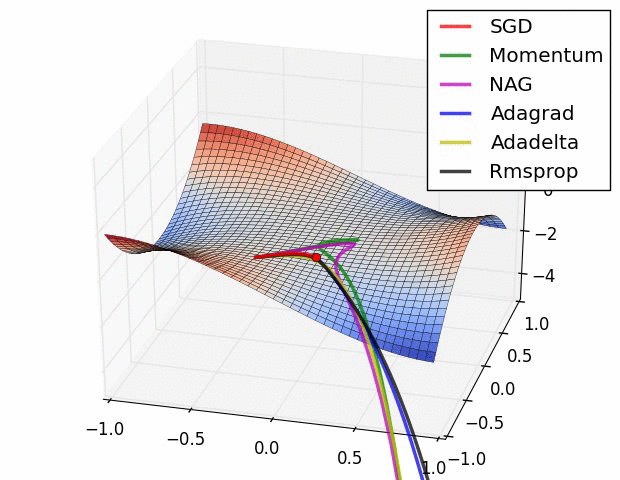
BP Review with Math





- 오타 수정
\[\begin{aligned} \frac{\partial E_1}{\partial H_1} &= \frac{\partial E_1}{\color{blue}{\partial y_1}} \cdot \frac{\color{blue}{\partial y_1}}{\partial H_1} \\ \frac{\partial E_1}{\partial H_1} &= \frac{\partial E_1}{\color{red}{\partial Y_1}} \cdot \frac{\color{red}{\partial Y_1}}{\color{blue}{\partial y_1}} \cdot \frac{\color{blue}{\partial y_1}}{\partial H_1} \end{aligned}\]$ \partial E_1 \over \partial H_1 $
\[\begin{aligned} \frac{\partial E_2}{\partial H_1} &= \frac{\partial E_2}{\color{green}{\partial y_2}} \cdot \frac{\color{green}{\partial y_2}}{\partial H_1} \\ \frac{\partial E_2}{\partial H_1} &= \frac{\partial E_2}{\color{orange}{\partial Y_2}} \cdot \frac{\color{orange}{\partial Y_2}}{\color{green}{\partial y_2}} \cdot \frac{\color{green}{\partial y_2}}{\partial H_1} \end{aligned}\]$ \partial E_2 \over \partial H_1 $
Keras BP 실습
- 신경망 학습 매커니즘
- Load data
- Define model
- Compile
- Fit
- Evaluate
1 | |


Fashin MNIST
1 | |

1 | |
Review
- 신경망(Neural Network)에서 사용할 초기 가중치(파라미터,parameter)를 임의 설정
- 설정한 파라미터를 이용하여 입력 데이터를 신경망에 넣은 후 순전파 과정을 거쳐 출력값(Output)을 수신
- 출력값과 타겟(Target, Label)을 비교하여 손실(Loss) 계산
- 손실(Loss)의 Gradient를 계산하여 Gradient가 줄어드는 방향으로 가중치 업데이트합니다.
이 때 각 가중치의 Gradient를 계산할 수 있도록 손실 정보를 전달하는 과정이 역전파(Backpropagation) - 얼마만큼의 데이터를 사용하여 가중치를 어떻게 업데이트 할 지 결정
이를 옵티마이저(Optimizer)라는 하이퍼파라미터로 선정(Stochastic or Batch 등)