목차
1주차
- 퍼셉트론(Perceptron)과 인공신경망(Artificial Neural Networks)
- 퍼셉트론(Perceptron), 가중치(Weight), 입력(Input)과 출력(Output)
- 역전파(Backpropagation)
- 경사 하강법(Gradient Descent), 학습률(Learning rate)
- 과적합(Overfitting)을 막기 위한 방법
- 가중치 감소/제한(Weight Decay/Constraint), Dropout, 조기 종료(Early Stopping)
- 신경망 하이퍼파라미터(Hyperparameter) 튜닝, 실험 추적 시스템
- Keras tuner, wandb
2주차
- 텍스트 전처리(Text Preprocessing)와 횟수 기반의 벡터화
- 불용어, 어간 추출(Stemming)과 표제어 추출(Lemmatization), BoW, TF-IDF
- 분산 기반의 벡터화와 임베딩(Embedding)
- 임베딩(Embedding), Word2Vec, OOV, fastText
- 언어 모델과 순환 신경망(RNN)
- 언어 모델(Language Model), RNN, LSTM, GRU, Attention
- 트랜스포머(Transformer)와 그 이후
- Transformer, Self-Attention, 사전 학습된 언어 모델, GPT, BERT
3주차
- 합성곱 신경망(CNN)과 이미지 처리
- Convolution, Pooling, Transfer Learning
- 구분(Segmenatation)과 객체 탐지(Object Detection)
- FCN, Unet, RCNN, YOLO
- 오토인코더(AutoEncoder)
- Latent Vector, 이상치 탐지(Anomaly Detection)
- GAN(Generative Adversarial Network)
- Generator vs Discriminator, DCGAN, CycleGAN
전문용어 없이 듣는 딥러닝의 모든 것
- 바로가기
- 1943년: Warren McCulloch
- 기계학습 = 사람학습
- 신경망 연구
- 1958년: Frank Rosenblatt
- 기존 신경망 모델을 발전
- 응용을 활용하여 실제 문제 해결
- XOR 문제(배타적 논리합): 퍼셉트론은 나쁜 학습법 - 민스키

- 1980: MLP(Multi Layer Perceptron)

- 1986: 역전파법

AI의 역사
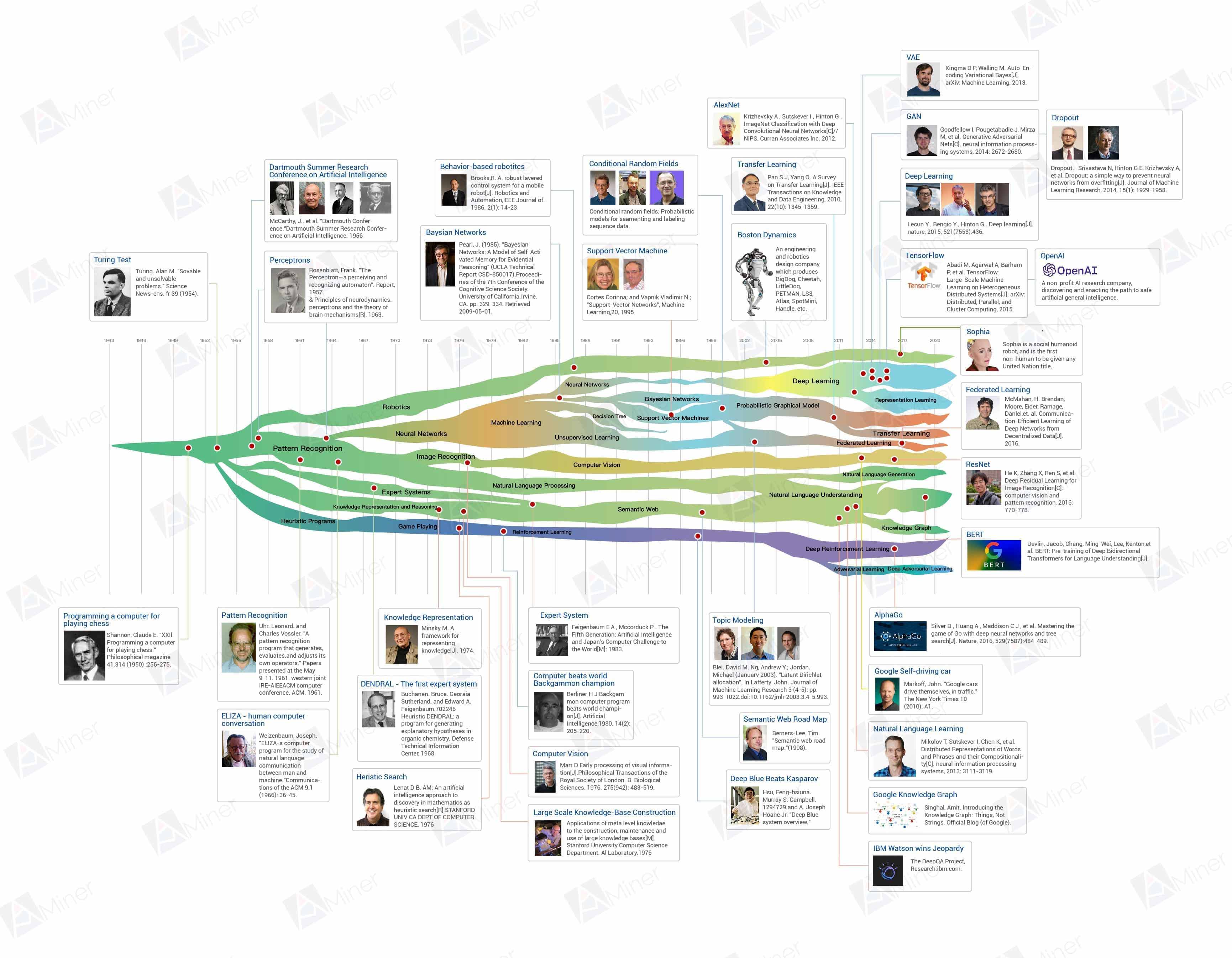
- 패턴 인식(Pattern Recognition)
- 신경망(Neural Networks)
- 머신러닝(Machine Learning)
- 딥러닝(Deep Learning)
- 이미지 인식(Image Recogition)
- 컴퓨터 비전(Computer Vision) → 딥러닝 기반 컴퓨터 비전
- 자연어 처리(Natural Language Processing) → 딥러닝 기반 자연어처리
- 자연어 이해(Natural Language Understanding)
- 자연어 생성(Natural Language Generation)
- 신경망(Neural Networks)
- 휴리스틱 프로그램(Heuristic Programs)
- 게임 기술(Game Playing)
- 강화학습(Reinforcement Learning) → 딥러닝 기반 강화학습
- 게임 기술(Game Playing)
- 로보틱스(Robotics)
Why Deep Learning?
- 1950년 처음 제시된 신경망 아이디어는 많은 주목을 받지 못했다.
- MLP의 발전 등으로 강력한 기술이 되었다.
- Object Detection, Segmentation, NLP 등 기존 머신러닝 알고리즘이 잘 못 풀던 영역에서도 사람보다 뛰어난 성과를 보인다.
발전 이유
- 핵심 알고리즘의 발전
- 딥러닝 프레임워크(Framework)의 발전 : Tensorflow, Keras, PyTorch 등
- GPU의 발전으로 인한 계산 속도 증가 : CUDA 와 같은 라이브러리 등장
- 벤치마크 데이터셋(Dataset) 등 기반이 되는 데이터셋 마련 : ImageNet, GLUE

How
- 신경망에 대한 거부감 없애기
- 새로운 개념을 글로 적거나, 말해보면서 제대로 알고 있는지 확인
Perceptron
- 뉴런을 모사하여 만들어진 신경망을 이루는 가장 기본 단위

- 프랑크 로젠블라트(Frank Rosenblatt)가 1957년 고안
- 퍼셉트론이 신경망(딥러닝)의 기원이 되는 알고리즘
- 다수의 신호를 입력으로 받아 하나의 신호를 출력
- 신호: 전류와 같은 일종의 흐름
- 퍼셉트론은 입력 데이터와 가중치가 연산의 흐름을 만들어 정보를 계속해서 전달
- 가중치는 전류에서 말하는 저항에 해당
- 저항이 낮을수록 큰 전류가 흐르지만, 반대로 퍼셉트론에서는 가중치가 클수록 강한 신호를 흘려보낸다.
- Perceptron = Perception + Neuron
- Perception : 무언가를 인지하는 능력
- Neuron : 감각 입력 정보를 의미있는 정보로 바꿔주는 뇌에 있는 신경 세포
- 뉴런이 감각 정보를 받아서 문제를 해결하는 원리를 따라한 인공 뉴런으로써 입력 값에 대해 가중치를 적용해 계산한 후, 확인해서 결과를 전달한다.
- 퍼셉트론은 자신이 내린 결과를 확인해서, 미래에는 더 나은 결정을 하도록 자기 자신을 수정한다.
- 하나의 뉴런만으로 아무것도 할 수 없음. 퍼셉트론도 마찬가지
- 하나의 노드(뉴런)으로 이루어진 신경망의 기본 구조이며, 다수의 입력값을 받아 하나의 출력값을 내보낸다.

- 노드는 입력값에 가중치(와 편향)가 곱해진 값을 모두 더하는 연산, 즉 선형 결합을 하고 활성화 함수를 적용한 후 그 값을 출력
- Bias(편향): 해당 Perceptron이 얼마나 쉽게 활성화 되는지를 조절하는 매개변수
수식
- $f$는 활성화 함수
- 먼저 가중치와 편향을 입력 신호와 연산한 값을 더한$\big(\sum\big)$ 뒤에, 활성화 함수$(f)$에 넣어준다.
$y = f \bigg[\sum(b + w_0x_0 + w_1x_1 + … + w_nx_n) \bigg]$
- 만약 활성화 함수가 위에서 구현했던 계단 함수라면
$ f(\mathbf {x} )={\begin{cases}1&{\text{if }}\ \mathbf {w} \cdot \mathbf {x} +b>0, \ 0&{\text{otherwise}}\end{cases}} $
Logic Gate
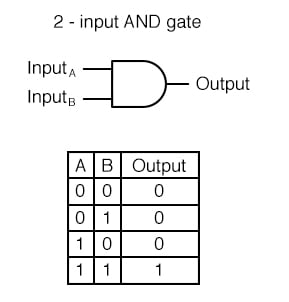
AND GATE
- 입력 신호가 모두 1(True)일 때 1(True)을 출력
1 | |
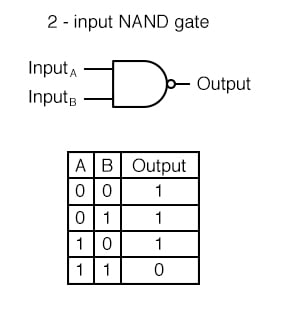
NAND GATE
- Not AND 의 줄임말로 AND GATE의 결과의 반대를 출력
1 | |
OR GATE
- 입력 신호 중 하나만 1(True)이라도 1(True)을 출력
1 | |
XOR GATE
- 배타적 논리합(Exclusive-OR)이라고도 불리는 GATE. 입력 신호가 다를 경우 1(True)을 출력
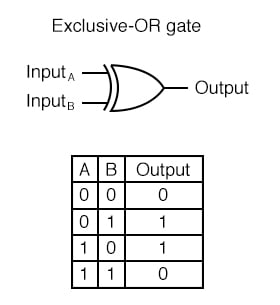
- 신경망이 논의되던 초기에 퍼셉트론의 한계로 지적되었던 것이 바로 XOR GATE 의 표현

- 여러 개의 선을 아무리 그어보아도 하나의 직선으로는 흰점과 검은점을 구분할 수 없다.
XOR 문제

- 퍼셉트론의 한계를 설명할 때 등장하는 XOR(exclusive OR) 문제
- XOR 문제는 논리 회로에 등장하는 개념
- 컴퓨터는 두 가지의 디지털 값, 즉 0과 1을 입력해 하나의 값을 출력하는 회로가 모여 만들어지는데, 이 회로가 ‘게이트(gate)’


- AND와 OR 게이트는 직선을 그어 결괏값이 1인 값(검은점)을 구별할 수 있다.
- 그러나 XOR의 경우 선을 그어 구분할 수 없다.
- 이는 인공지능 분야의 선구자였던 MIT의 마빈 민스키(Marvin Minsky) 교수가 1969년에 발표한 <퍼셉트론즈(Perceptrons)>라는 논문에 나오는 내용
- ‘뉴런 → 신경망 → 지능’이라는 도식을 따라 ‘퍼셉트론 → 인공 신경망 → 인공지능’이 가능하리라 꿈꾸던 당시 사람들은 이것이 생각처럼 쉽지 않다는 사실을 깨닫게 된다.
- 알고 보니 간단한 XOR 문제조차 해결할 수 없었던 것
- 이 논문 이후 인공지능 연구가 한동안 침체기를 겪게 된다.
- 10여 년이 지난 후에야 이 문제가 해결되는데, 이를 해결한 개념이 바로 다층 퍼셉트론(multilayer perceptron)
- XOR 문제의 해결은 평면을 휘어주는 것!
- XOR 문제를 해결하기 위해서 두 개의 퍼셉트론을 한 번에 계산할 수 있어야 한다.
- 이를 가능하게 하는 숨어있는 층이 은닉층(hidden layer)

신경망
- 1943년경 뇌의 신경 활동을 수학으로 표현하고자 한 아이디어와 1957년에 로젠블라트(Rosenblatt)가 고안한 퍼셉트론이 발전
- ANN(Artificial Neural Networks), 즉 인공 신경망은 실제 신경계의 특징을 모사하여 만들어진 계산 모델
- 인공 신경망의 기본 구조인 퍼셉트론은 실제 뇌 신경망의 기본 구조인 뉴런(Neuron)을 모사하여 제작
- 뉴럴넷(Neural-Net)

신경망의 기본 형태(가중치, 편향 연산)

- 원으로 표현된 부분을 뉴런(Neuron) 혹은 노드(node)
- 입력 신호($x_0, x_1, …$)가 입력되면 각각 고유한 가중치($w_0, w_1, …$)가 곱해진다.
- 다음 노드에서는 입력된 모든 신호를 더해준다.($\sum$).
- 각 노드에서의 연산값이 정해진 임계값(Threshold Logic Unit)을 넘을 경우에만 다음 노드들이 있는 층(layer)으로 신호를 전달한다.
- 목표: 복잡한 데이터 속에서 패턴을 발견할 수 있는 알고리즘으로서의 인공 신경망을 만드는 것
Activation Func
- 활성화 함수는 인공지능의 많은 알고리즘에서 다양한 형태로 사용된다.
- 어떠한 활성화 함수를 사용하느냐에 따라 그 출력 값이 달라지기 때문에, 적절한 활성화 함수를 사용하는 것은 중요하다.
- 활성화 함수: 어떠한 신호를 입력받아 이를 적절한 처리를 하여 출력해주는 함수
- 각 노드에서의 연산값이 정해진 임계값을 넘을 경우에만 다음 노드들이 있는 층으로 신호를 전달
- 신경망에서 각 노드는 활성화 함수를 갖고 있다.
- 각 층에는 같은 종류의 활성화 함수를 사용한다.
- 인공신경망에서 활성화 함수는 다음 층으로 신호를 얼마만큼 전달할지 결정한다.
- 그래서 간혹 Transfer func(전달함수)라고 부른다.

- 가장 간단한 활성화 함수인 3개(Step, Sigmoid, ReLU)
- 활성화 함수는 신경망의 output을 결정하는 식
- 각 뉴런은 가중치를 가지며 이것은 input number와 곱해져 다음 레어로 전달
- 이 때 활성화 함수는 현재 뉴런의 input을 feeding하여 생성된 output이 다음 레이어로 전해지는 과정 중 역할을 수행하는 수학적인 게이트
Step func
- 입력 값이 임계값을 넘기면 1을 출력하고, 그렇지 않으면 0을 출력하는 함수
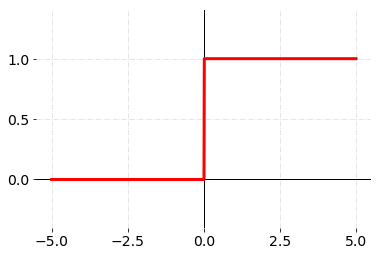
1 | |

Sigmoid func
- 신경망이 경사 하강법을 통해 학습을 진행하기 위해서는 ‘미분’과정이 필요한데 Sigmoid가 해결해준다.

1 | |

ReLU func
- 많이 사용되는 활성화 함수
1 | |

구현

초기 상태 설정
- 가중치와 편향의 값은 임의로 지정
1 | |
순전파 함수 정의
- 순전파(Forward Propagation): 가중치와 편향의 연산을 반복하며 입력값을 받아 출력값으로 반환하는 과정
- 딥러닝에서 입력 데이터가 있으면 신경망을 따라서 쭉 신호를 전파해서(가중치와 편향의 연산 반복) 최종 출력을 만들어가는 과정
1 | |
계산한 값 출력
1 | |
- 위 코드는 학습없이 단순히 입력 값에 가중치를 연산하여 출력을 내는, 즉 한 번의 순전파가 일어나는 간단한 신경망
가중치 행렬과 입력 신호의 연산
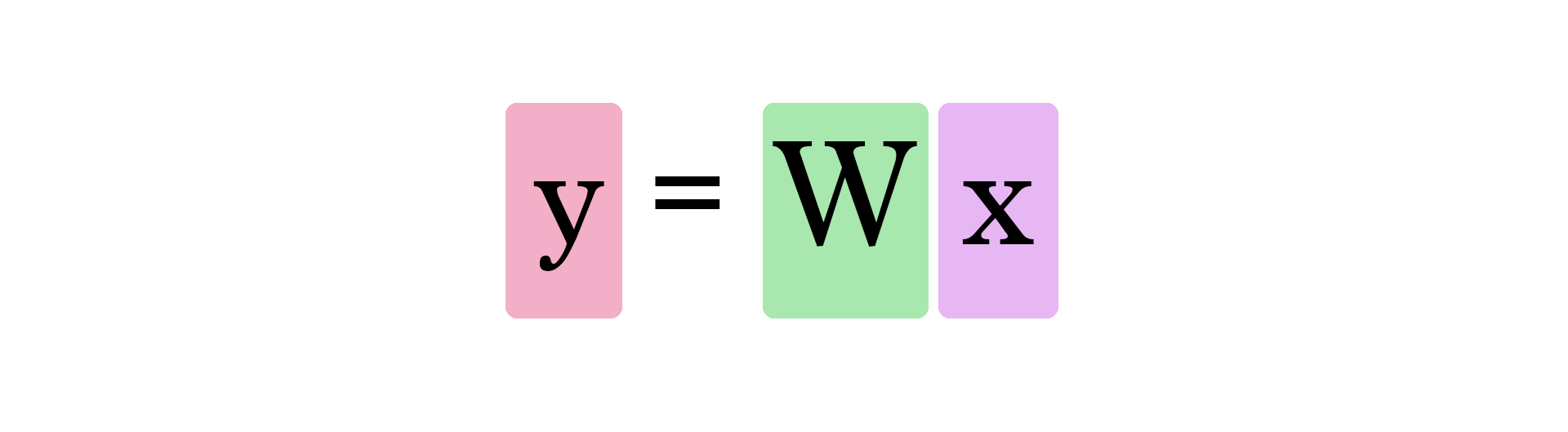

- 신경망은 노드가 가중치로 연결되어 입력 신호와 연산한 뒤에 출력값으로 내보내는 함수라고도 할 수 있다.
- 가중치를 지속하여 수정하면서 적절한 가중치를 찾는 과정을 학습(Training, Learning)이라고 한다.
여러가지 신경망 구조
Layer
Input Layer
- 데이터셋이 입력되는 층
- 입력되는 데이터셋의 특성(Feature)에 따라 입력층 노드의 수가 결정
- 보통 입력층은 어떤 계산도 수행하지 않고 그냥 값들을 전달하기만 하는 특징을 가지고 있다.
- 그렇기 때문에 신경망의 층수(깊이, depth)를 셀 때 입력층은 포함하지 않는다.
Hidden Layer
- 입력층으로부터 입력된 신호가 가중치, 편향과 연산되는 층
- 일반적으로 입력층과 출력층 사이에 있는 층을 은닉층이라고 부른다.
- 은닉층에서 일어나는 계산의 결과를 사용자가 볼 수 없기 때문에 ‘은닉(Hidden)층’ 이라는 이름이 붙었다.
- 은닉층은 입력 데이터셋의 특성 수와 상관 없이 노드 수를 구성할 수 있다.
- 일반적으로 딥러닝(Deep Learning)이라고 하면 2개 이상의 은닉층을 가진 신경망
- 은닉층의 수가 늘어나고 더 좋은 학습 방법이 개발되면서 복잡한 데이터의 구조를 학습할 수 있게 되었다.
- 이렇게 복잡한 신경망이 다른 알고리즘이 세웠던 성능을 갱신하면서 딥러닝이 유명해졌다.
Output Layer
- 가장 마지막에 위치한 층이며 은닉층 연산을 마친 값이 출력되는 층
- 문제 종류에 따라서 출력층을 잘 설계하는 것이 중요하다.
이진 분류(Binary Classification)
- 활성화 함수로는 시그모이드(Sigmoid) 함수를 사용하며 출력층의 노드 수는 1로 설정
- 출력되는 값이 0과 1 사이의 확률값
다중 분류(Multi-class Classification)
- 활성화 함수로는 소프트맥스(Softmax) 함수를 사용하며 출력층의 노드 수는 레이블의 클래스(Class) 수와 동일하게 설정
회귀(Regression)
- 일반적으로는 활성화 함수를 지정해주지 않으며 출력층의 노드 수는 출력값의 특성(Feature) 수와 동일하게 설정(항등 함수)
- 단순히 하나의 수를 예측하는 문제라면 1
TF Exemple
MNIST
1 | |
- ❓ Flatten 역할
- ❓ 마지막 Dense 층의 숫자 10
- ❓ 마지막 Dense 층의 activation softmax
- ❓ compile 이 있는 부분에서 loss 함수
Why Powerful?
- 깊은 신경망, 즉 딥러닝은 복잡한 데이터셋에서도 패턴을 잘 찾아내어 분류, 회귀 등의 문제를 뛰어난 성능으로 풀어낸다.
- 이미지, 텍스트 데이터와 같이 차원이 많고 복잡한 데이터에서 패턴을 찾으려면, 매우 복잡한 특성 조합이 필요하다.
Representation Learning(표현학습)
- 머신러닝을 수행할 때에는 직접 데이터셋이 가진 특성(Feature)을 최대한 파악한 후 가장 중요한 특성만을 설계하고 찾아내야 했다.
- 그 과정이 Feature Engineering을 바탕으로 한 전처리
- 전처리 이후에 머신러닝 모델에 넣어주어야 모델의 성능을 올릴 수 있었고 전처리를 생략한다면 성능이 잘 나오지 않았다.
- 반면에 신경망은 데이터에서 필요한 특성을 알아서 조합하여 찾아낸다.
- 최소한의 전처리만 해준 후에 모델에 넣어도 꽤 성능이 잘 나오게 된다. 즉, 심화된 특성 공학을 사용해 특성 간의 관계를 찾아낼 필요가 없다.
- 스스로 특성 관계를 찾아내는 것을 표현 학습(Representation learning)
- ❓ 그렇다면 신경망의 구조를 어떻게 설계하는 것이 가장 좋을까? 좋은 신경망 구조란 무엇일지 각자 생각해보자
Neural Network in Python
1 | |

1 | |
backpropagation(역전파)
- 출력 오차를 줄이기 위한 경사 하강법 이용
- 손실(error, cost)을 계산하기 위해 실제 타겟값(target)과 출력값(output)의 차이를 계산
- 경사 하강법(Gradient descent): 손실 값이 최소가 되는 가중치(weight)를 찾는 방법
- 역전파 알고리즘은 경사 하강법에 필요한 미분값을 빠르고 효율적으로 찾는 알고리즘
MSE 미분
- 손실 함수(Cost function)로 MSE(Mean Squared Error)를 사용할 때,
가중치에 대해 도함수를 아래와 같은 수식으로 나타낼 수 있다. 참조 링크
와 같은 형태가 되고 $o_i$ 를 $w_j$에 관해 편미분 하면
\[\frac{\partial}{\partial w_j} o_i\] \[= \frac{\partial o_i}{\partial \text{net}_i}\frac{\partial\text{net}_i}{\partial {w_j}}\]라고 쓸 수 있다. 벡터 계산 코드로 구현하면 다음과 같고 이를 가중치 업데이트에 사용한다.
da= $\partial E/\partial A$ (MSE를 미분하여 나오는 값)dz= $\partial E/\partial z$dw,db= 각각 가중치(weight), 편향(bias) 업데이트 값
1 | |
Iris
1 | |

1 | |

1 | |

References
동영상
- 인공 신경망으로 해보는 선형 회귀(Linear Regression) - (03:25~08:50)
- 머신러닝 개발자들의 일반적인 실수, 과적합 (Overfitting, 4분)
- 교차검증(Cross Validation, 3분)
- 데이터 split & shuffle for ML (7분)
- 신경망이란 무엇인가? 1장.딥러닝에 관하여 - 3 Blue 1 Brown
- Neural Network - Andrew Ng
웹페이지
- Alammar, Jay A Visual and Interactive Guide to the Basics of Neural Networks.
- SINGLE LAYER NEURAL NETWORK - PERCEPTRON MODEL ON THE IRIS DATASET USING HEAVISIDE STEP ACTIVATION FUNCTION
- 딥러닝의 선형 vs 비선형
서적
Review
- input layer(입력층): 노드의 개수는 입력값에 따라서 자동으로 정해진다.
- hidden layer(은닉층): 노드의 개수를 조절할 수 있다.
- output layer(출력층): 신경망 모델에서 출력값을 의미하며, 이 출력층의 노드 개수, 모양에 따라서 모델의 정의가 달라질 수 있다.

- Input Layer: A
- Hidden Layer: B
- Output Layer: D
- Neuron(Node): C
- Weight: F
- Bias: E
- Activation Function: G
- Node Map: H
- Iteration: I
- Epoch: J
1 | |
- Node Map: 784 x 256 x 10
1 | |
- 위 코드를 실행하게 되면, (60000, 784) 형태로 출력
- 만일, 100장의 이미지가 이 모델에 입력된다면 출력된 array는 어떤 형태로 구성되어 있을까?
- (100, 784)
- TensorFlow에서는 데이터의 개수를 주로 array의 가장 첫 번째 차원에서 다룬다.
1 | |
- 한 번에 100장의 이미지가 모델을 통과한다고 할 때, (a)에서의 입력 값과 출력 값의 array는 각각 어떤 형태로 구성되어 있을까?
- 입력: (100, 784), 출력: (100, 256)
Advanced
강의 자료 작성

Perceptron이란, 무언가를 인지하는 능력을 뜻하는 Perception과 감각 입력 정보를 의미 있는 정보로 바꿔주는 뇌의 신경세포를 뜻하는 Neuron이 합하여 만들어진 단어입니다. 뉴런이 감각 정보를 받아서 문제를 해결하는 원리를 따라 한 인공 뉴런으로써, 입력값에 대해 가중치를 적용해 계산한 후, 결과를 전달합니다. 하나의 뉴런으로 이루어진 신경망의 기본 구조이며 다수의 입력값을 받아 하나의 출력값을 내보낸다는 특징이 있습니다. 뉴런은 입력값에 가중치와 편향을 곱해진 값을 모두 더하는 연산을 하고 활성화 함수를 적용한 후 그 값을 출력합니다. 활성화 함수는 뒤 슬라이드에서 알아보겠습니다. 학습을 지속하며 손실 값이 최소가 되는 적절한 가중치를 찾는 것이 DL Model에서 중요하다고 할 수 있습니다. 편향이란 해당 Perceptron이 얼마나 쉽게 활성화되는 지를 조절하는 매개변수입니다.

Neural Network에서 각 층에 대해 알아보겠습니다. Input, Hidden, Output으로 구성되어 있으며, Input Layer는 데이터가 입력되는 층으로 입력되는 데이터셋의 특성에 따라 입력층 노드의 수가 결정됩니다. 보통 입력층은 어떤 계산도 수행하지 않고 그저 값만 전달합니다. Hidden Layer는 입력층으로 부터 입력된 신호가 가중치, 편향과 연산되는 층입니다. 은닉층에서는 입력 데이터셋의 특성 수와 상관없이 노드를 구성할 수 있으며 일반적으로 Deep Learning은 2개 이상의 은닉층을 가졌습니다. 가장 마지막에 위치한 층이 Output Layer이며 문제 종류에 따라 출력층을 잘 설계하는 것이 중요한데, 보통 이진 분류 문제에서는 Sigmoid func을 사용하며 출력층 노드 수는 1로 설정하고, 다중 분류 문제에서는 Softmax func을 사용하며 출력층의 노드 수는 Label Class 수와 동일하게 설정합니다. 회귀 문제에서는 활성화 함수를 지정해주지 않으며 노드 수는 출력값의 특성 수와 동일하게 설정합니다.

어떤 활성화 함수를 사용하느냐예 따라 출력 값이 다양해지기 때문에 적절한 함수를 사용하는 것이 중요한데, 활성화 함수란, 어떠한 신호를 입력 받아 이를 적절한 처리를 하여 출력해주는 함수입니다. 인공 신경망에서 활성화 함수는 다음 층으로 신호를 얼만큼 전달할 지 결정하는데, 간단한 세가지 함수에 대해 알아보겠습니다. 먼저 Step function은 입력 값이 임계값을 넘기면 1을 출력하고 그렇지 않으면 0을 출력하는 함수입니다. 그런데 신경망이 경사 하강법을 이용해서 학습을 진행하기 위해서는 ‘미분’과정이 필요합니다. 그 과정을 Sigmoid 함수가 해결해줍니다. 다음 ReLu 함수는 가장 많이 사용되는 활성화 함수로써 Sigmoid와 tanh가 갖는 Gradient Vanishing 문제를 해결하기 위한 함수입니다. 학습이 빠르고, 연산 비용이 적고, 구현이 매우 간단하다는 특징이 있습니다.
Machine Learning Model과의 비교
Classifier
DL
1 | |
ML
CatBoostClassifier
1 | |
Regressor
DL
1 | |
- loss가 무조건 줄어드는 것 만은 아니다.

ML
- LGBM regressoion 간단하게 구현
1 | |
- 머신러닝 모델보다 딥 러닝 모델이 더 나을 것이라고 했지만, 기본과제든 도전과제든 머신러닝 모델이 더 좋은 성능을 보였다.
- 아마 두개의 데이터셋 모두 전처리가 크게 필요없는 데이터셋이라서 그런 것 같기도하고, 현재 존재하는 머신러닝 모델들의 성능도 뒤지지 않기 때문에 그런 것 같다. 그것도 아니라면 딥 러닝 모델링 더 배워야 할 수도?
- 결론: 전처리를 빡세게만 한다면 머신러닝 모델! 전처리 하기 귀찮다면 딥러닝 모델!